我们最近在 LM Studio 中发布了 mlx-engine v1.8.5。这个更新通过对 KV 缓存进行检查点保存,显著提升了重复、长上下文 agentic 工作流的性能。它还为 VLM 请求加入了连续批处理能力。这项工作是开源的;你可以在这里查看 PR。
在这篇文章中,我会解释它解决的缓存复用问题、为什么当前开源 LLM 模型让回滚变得更困难,以及新的磁盘后端缓存是如何工作的。我们的基准测试显示:额外 RAM 使用量最多可降低 80%,吞吐量最多提升 2 倍,图像请求处理速度最多提升 3.5 倍。
可以看看 Adrien 使用新版 mlx-engine 在本地通过 codex --oss 审查一个 URL 短链接应用的视频:
https://x.com/adrgrondin/status/2057186643086278782?s=20。
什么是 mlx-engine?
MLX Engine(mlx-engine)是一个采用 MIT 许可证的推理引擎,针对 Apple 芯片进行了优化。它由 LM Studio 创建并维护,使用 Apple 的 MLX 机器学习库,并建立在 mlx-lm、mlx-vlm 等项目之上。MLX Engine 是 LM Studio 用于所有 MLX 推理任务的后端。
当前模型架构,以及 mlx-engine 的不足
目前最受欢迎的两个开源模型是 Qwen 3.5(以及 3.6)和 Gemma 4。作为各自模型架构的一部分,它们都使用了一些巧妙手段来降低大上下文长度下的 KV 缓存大小。Qwen 3.5 使用混合架构,Gemma 4 使用滑动窗口架构。这些注意力策略能降低大上下文长度下的内存使用,但也让 KV 缓存无法任意回滚。
我们来看一下 Gemma 4 如何处理推理。这个例子聚焦于 Gemma 4 E2B;它交替使用“局部”注意力层(512 个 token 的滑动窗口)和“全局”注意力层。
步骤 1:Prompt prefill。为系统提示词和用户消息计算 KV 缓存。 步骤 2:Decode。在计算助手推理内容和助手消息的同时,逐步构建 KV 缓存。 步骤 3:Rewind。将 KV 缓存裁剪回步骤(1),并追加助手消息,但不包含此前的推理内容。

因此,推理引擎必须解决的一个关键问题是:在回滚 KV 缓存以准备后续响应时,如何避免重复计算。
我们如何改进 mlx-engine 中的提示词缓存
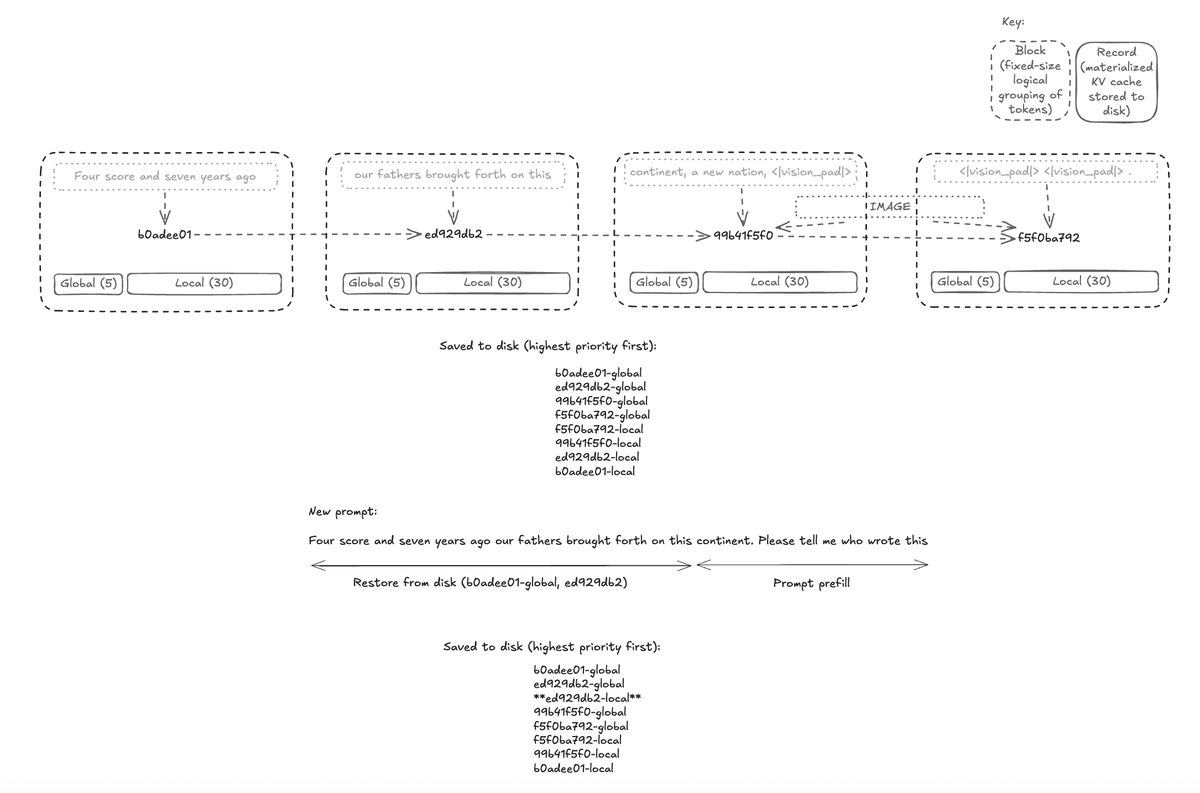
针对这些 agentic 用例,我们设计了一套 KV 缓存回滚方案。通过将提示词缓存保存到磁盘并从磁盘恢复,后续请求的 KV 缓存不再需要重新计算。
保存 KV 缓存到磁盘
在每 256 个 token 的边界复制并存储这些 KV 缓存,可以让我们在对应的 KV 缓存张量仍然存在时恢复精确的缓存前缀。如果提示词中的某一部分被编辑过、从未计算过,或已从磁盘缓存中被驱逐,mlx-engine 就会回退为重新计算这一后缀。256 个 token 足够小,可以避免在重新计算上浪费太多工作量;同时也足够大,可以让磁盘缓存保持高效。
首先,在每个 256 token 边界(sequence len % 256 == 0),将局部注意力层的 KV 缓存副本流式发送到磁盘写入后端。当模型处理提示词或生成新 token 时,一个后台磁盘写入进程会同时运行。在每个 256 token 边界,系统会复制最近 256 个 token 对应的 KV 缓存,并发送给磁盘写入器,随后由它将该块持久化到磁盘。
由于 Apple 芯片采用统一内存架构,我们会把局部注意力 KV 缓存提交到磁盘,并将其从内存中驱逐。这样可以确保 mlx-engine 的内存占用随活跃序列扩展,而不是随所有曾经见过的序列扩展。
从磁盘恢复 KV 缓存
首先,为每个 256 token 块计算一个 key。然后,确定需要取回哪些全局和局部 KV 缓存块。根据提示词对应的 key 列表和缓存类型,从磁盘尽可能多地加载 KV 缓存。对于那些从未计算过 KV 缓存(或其 KV 缓存已从磁盘中被驱逐)的提示词片段,则安排这些片段执行 prompt prefill。磁盘缓存是一个 LRU 存储;因此,每当我们向磁盘存储保存或从中加载时,该存储都会驱逐最近最少使用的 KV 缓存张量。
这能确保磁盘存储针对实际使用模式进行优化。如果引擎收到的是使用同一系统提示词的短提示词请求,那么系统提示词的局部注意力 KV 缓存不会被驱逐,而过期会话的 KV 缓存会被驱逐。反过来,如果引擎只接收同一个不断增长的会话请求,较早的局部注意力 KV 缓存就会被驱逐,以便为更长的全局注意力 KV 缓存腾出空间。
磁盘缓存设计
我们将磁盘缓存设计为在模型卸载后自动清理。换句话说,这个缓存是临时的,不会留下持久文件。
磁盘缓存是一个 scratch file,而不是装满独立缓存文件的文件夹。我们会把许多缓存记录打包进这一个文件中。每个 KV 缓存条目都是一个序列化后的 safetensors blob,引擎则维护一张内存表,记录:“条目 X 从字节偏移 Y 开始,长度为 Z 字节。”当 KV 缓存条目被驱逐时,它们占用的字节范围会归还给空闲列表,并被后续记录复用;如果空闲空间到达了文件末尾,文件就会被缩小。
我们通过操作系统在 /tmp 中的临时文件机制,并将所有查找元数据都视为仅在模型生命周期内有效的状态,来保证磁盘缓存的临时性。模型卸载时,缓存存储会清空其内存索引并关闭 scratch file。如果模型进程退出,操作系统会关闭文件句柄并释放存储空间。
以及,连续批处理
我们还为视觉模型运行器加入了连续批处理。关于连续批处理的实现和收益,已经有很多文章讨论过;Hugging Face 有一篇很好的解释文章。
连续批处理允许用户用同一个模型并发处理多个请求。结合前面描述的 KV 缓存改进,mlx-engine 现在已经可以用于严肃的 agentic 负载。
基准测试
为了让性能改进更具体,我们在一台配备 36 GB RAM 的 M3 Max MacBook Pro 上,使用 lmstudio-community/Qwen3.6-27B-MLX-4bit,运行了几组端到端的 LM Studio API 基准测试。
这些基准测试聚焦于本次更新旨在改善的工作负载:并行聊天、长提示词处理,以及重复的高分辨率图像提示词。
基准测试:并行聊天吞吐量
设置:模型以 parallel=4 加载,然后通过 LM Studio API 并发发送四个短聊天请求。每个响应都允许自然停止。
结果:对于这个四路并行聊天负载,mlx-engine v1.8.5 的端到端完成速度约快 2.2 倍,输出 token 数量几乎相同。
基准测试:并行长提示词下的内存使用
设置:模型以 parallel=4 加载,然后通过 LM Studio API 并发发送四个大型提示词。我们在模型加载后和运行完成后分别测量 RAM 使用量。
结果:对于这个并行长提示词负载,mlx-engine v1.8.5 在运行后使用的额外 RAM 约减少 82%,同时保持了相近的耗时,并带来略高的总 token 吞吐量。这正是将非活跃提示词缓存记录移出统一内存所带来的预期收益。活跃序列仍然需要常驻内存,但陈旧缓存记录不再需要不断累积在 RAM 中。
基准测试:重复的高分辨率图像提示词
设置:同一个图像提示词被发送两次,每次请求只生成一个 token。这样可以隔离出处理图像展开后的提示词以及恢复提示词缓存的成本。
结果:对于这个重复的高分辨率图像提示词,mlx-engine v1.8.5 完成第二次请求的速度约快 3.5 倍。收益来自于恢复了图像展开后提示词缓存的大部分内容。
你也可以在 Mac 上用 LM Studio 试试看:https://lmstudio.ai/download