星期一,2026 年 6 月 1 日 - 26 分钟
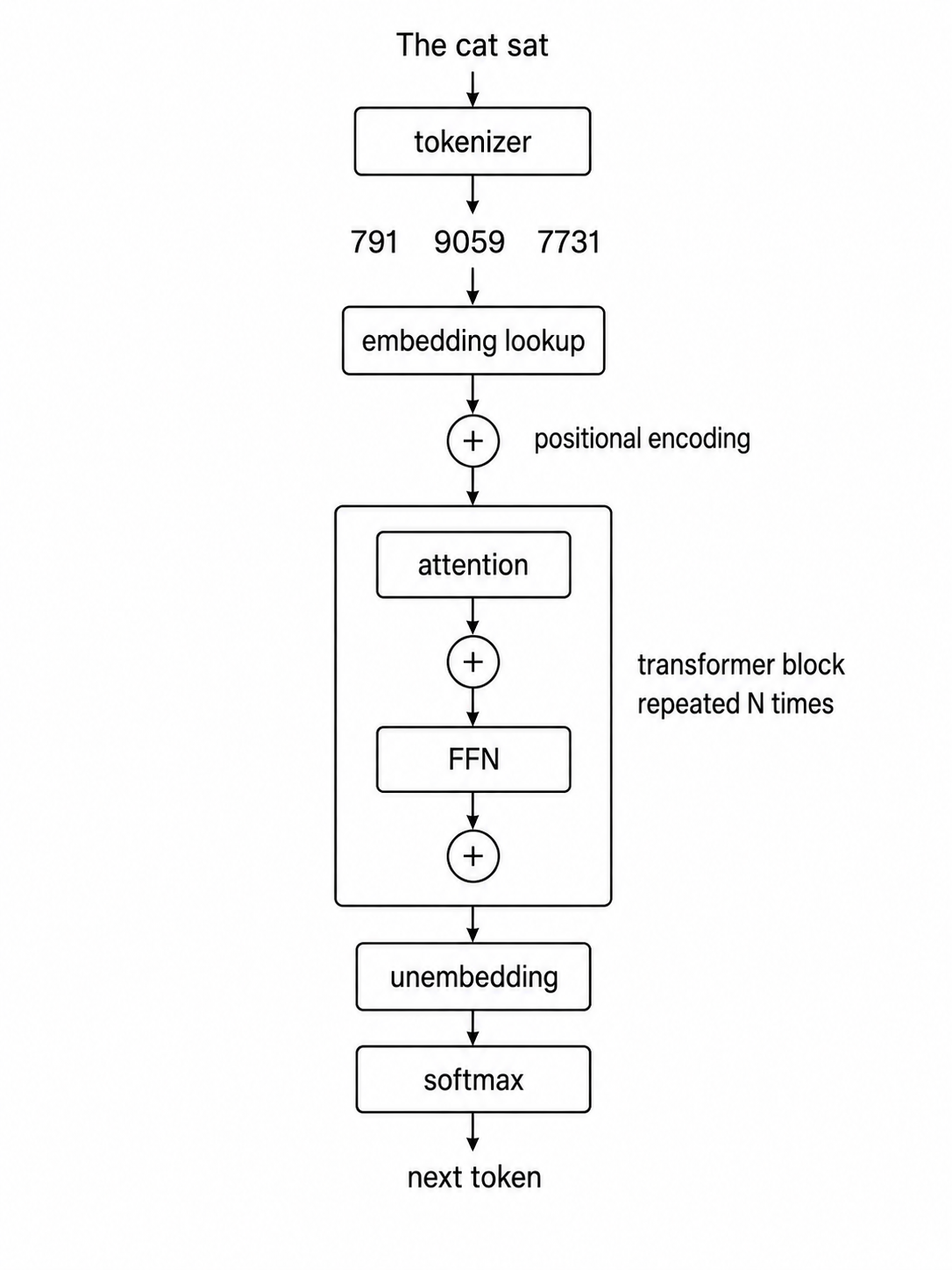
这篇文章会带你走一遍 LLM 是如何工作的。现代 LLM 大多是把 transformer block 一层又一层堆起来构成的,所以只要理解 transformer 这套机器的运转方式,就已经走完了大半程。
我会讲现代基于 transformer 的 LLM 内部最核心的机制,但不会塞进那些黏糊糊的数学细节。别误会,你确实应该学数学,不过这篇可以先当作一份入门导览。
大多数现代 LLM 都共享同一套 transformer 家族骨架。差异主要来自它们用什么数据训练、规模和配置怎么选,以及之后又做了哪些后训练。读完之后,你应该能看懂许多现代 LLM 论文或模型卡,知道每一节说的是架构里的哪一块。
路线是这样的:
- Token:一串文本如何变成一串整数
- Embedding:这些整数如何获得含义
- 位置编码:模型如何知道 token 的顺序
- Attention:token 如何彼此交换信息
- Multi-head attention:模型如何同时追踪多种关系
- Feed-forward network:模型中很大一部分“已存结构”所在的位置
- Residual stream 和 layer normalization:是什么让很深的堆叠可以训练
- 预测下一个 token:模型实际输出什么,生成循环如何工作
- 架构 vs 训练好的权重:现代 LLM 大体共享什么,又有哪些不同
文中会穿插一些小解释,让任何背景的读者都能跟上。
Tokenization
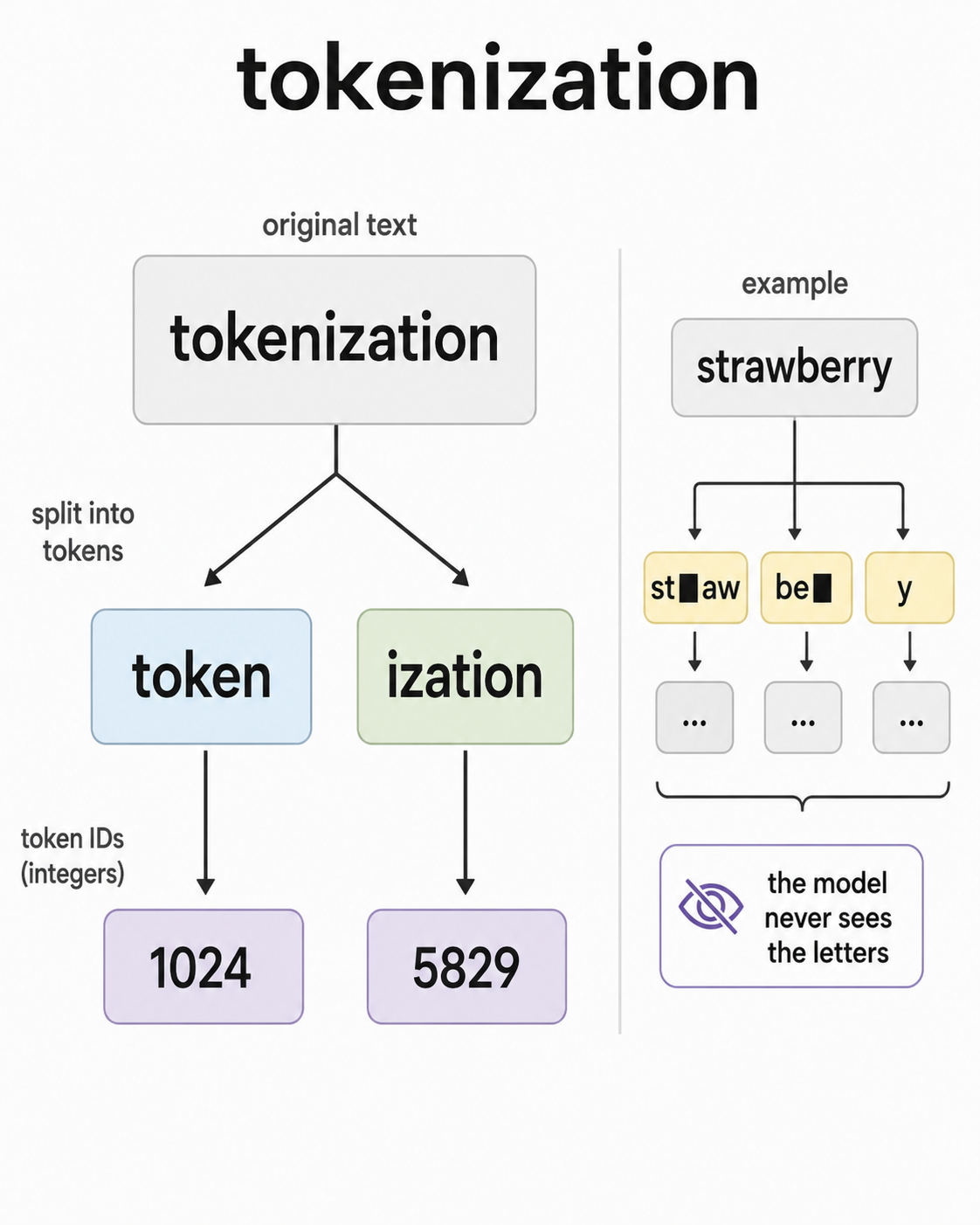
模型并不直接阅读文本。它们读取的是整数 ID。把你的 prompt 转换成这一串整数的步骤,就是这里要讲的第一步。
这个转换步骤叫做 tokenization。Tokenizer 接收一段字符串,输出一串整数,其中每个整数都指向固定词表里的一个条目。现代 LLM 的词表通常包含几万到几十万个条目。
小解释:token ID
Token ID 是模型用于表示某个词表条目的整数。模型处理的是这个数字,而不是写出来的词本身。
Token 通常不是完整单词,而是子词片段。单词 “tokenization” 可能会被拆成 [“token”, “ization”]。单词 “running” 可能会被拆成 [“run”, “ning”]。这么做是为了效率。整词词表太大,而且不容易泛化到新词。字符级词表又太小,会迫使模型从零开始学习最简单的模式。子词 tokenization 正好处在中间:常见片段会变成单个 token,罕见或新出现的词则由更小的片段组合出来。
小解释:词表
词表是 tokenizer 固定的片段列表。每个片段都有一个 ID,模型只能直接接收来自这张表的 ID。
这个取舍会出现在一些人们没想到的地方。经典例子是:问 LLM “strawberry” 里有几个 R。LLM 以前常常答错。这并不一定是模型不会计数,而是因为模型并不是直接在字母上操作,它只是在处理 token ID,而这些 ID 恰好拼出了一个人类会逐字母拆开的单词。
不同模型家族使用不同的 tokenizer。GPT 模型使用 Byte Pair Encoding 的变体。SentencePiece 常见于 LLaMA 风格的模型。这个选择会影响计算量(token 越少,工作越少),也会影响多语言覆盖等事情,但基本形态是一样的:文本进去,整数出来。
现在 prompt 已经是一串整数,下一步就是赋予这些整数含义。
Embeddings
像 1024 这样的 token ID 只是一个行索引。它本身没有任何含义。真正给它含义的,是一张叫做 embedding matrix 的巨大表。
每个模型都有这样一张表。词表里的每个条目对应一行,每一行都是一串很长的数字向量。每一行的长度就是模型的 hidden size。在很多 7B 级别的模型里,这意味着每个 token 有 4,096 个数字。更大的模型通常会使用更宽的向量。
小解释:向量
向量是一串数字。在 transformer 里,每个 token 都会变成一个向量,这样模型才能对它做数学运算。
当 tokenizer 把一个整数交给模型时,模型会查找对应的那一行,并改用这条向量。这个向量就是这个 token 的 embedding。它是模型对这个 token “含义”的表示,是在训练过程中学出来的。
小解释:embedding matrix
Embedding matrix 是一张查找表。输入 token ID,输出学到的向量。
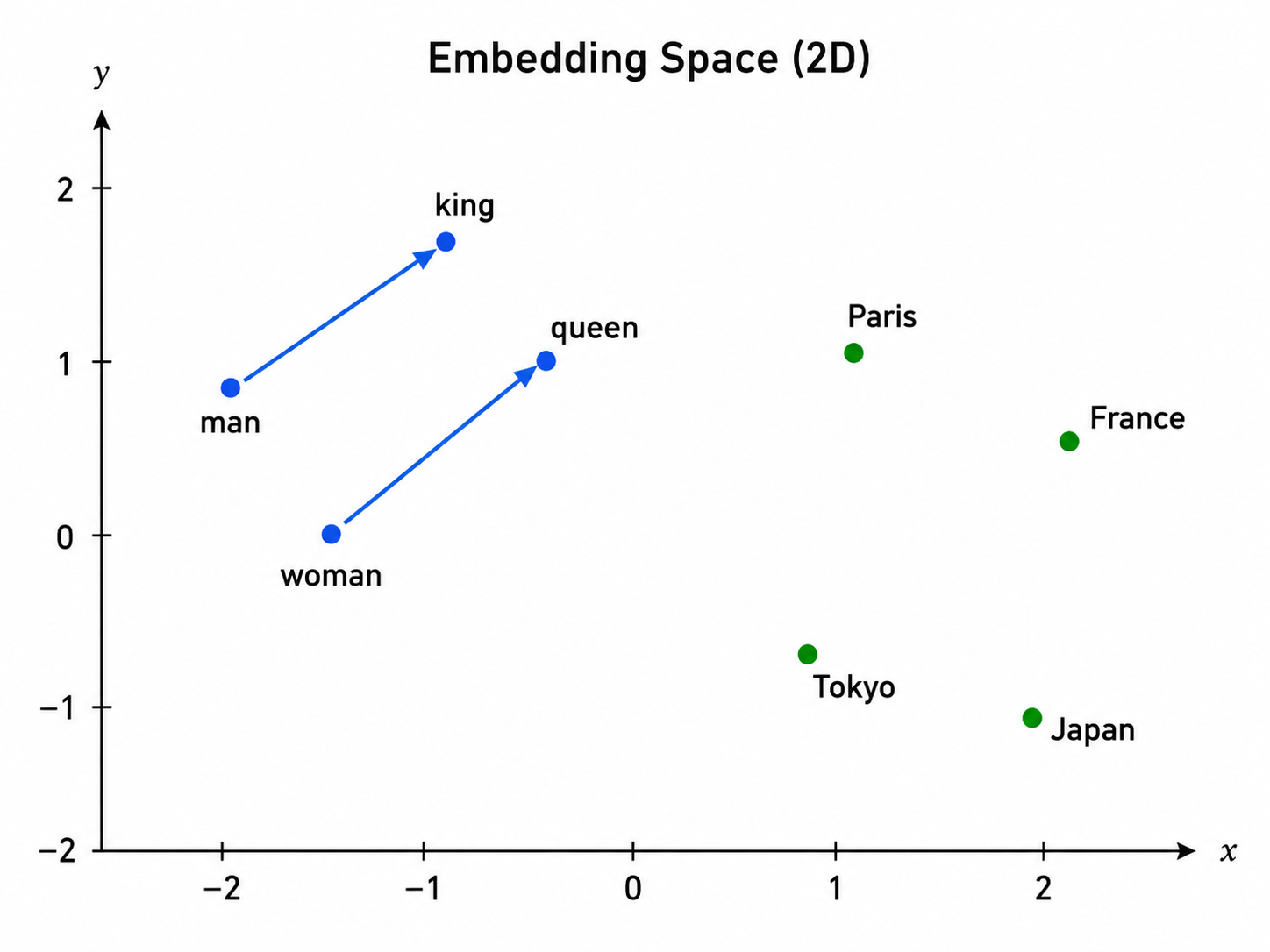
这些 embedding 有一个有趣的性质:语义相近的 token 最终会拥有相近的向量。“king”的向量会在空间中接近“queen”的向量,“Paris”的向量会接近“France”。这些都不是硬编码进去的。它们是在足够多文本上训练后涌现出来的,模型学会这些位置,是因为这样能更好地预测文本。
你可以对 embedding 做算术,有时还真能奏效。最著名的例子是 king − man + woman ≈ queen。Embedding 空间的几何结构承载了真实的语义结构,哪怕没人明确告诉模型要这样构建。
有一点值得说清楚:到这个阶段,每个 token 都已经被替换成了它的 embedding,但 embedding 本身并不会说明这个 token 位于序列中的哪里。“dog”的向量是同一个向量,无论 “dog” 是你 prompt 里的第一个词还是第五个词。这就是问题所在。
位置编码填补的正是这个空白。
Positional encoding
普通的 self-attention 本身没有内建的词序表示。没有某种位置信号,它就没有直接办法知道 “dog” 是出现在 “bites” 前面,而不是后面。
词序会改变含义。所以模型还需要另一块东西:它需要一种方式,把每个 token 的位置注入到数学运算里。
小解释:位置编码
位置编码是模型获取顺序信息的方式。它告诉模型每个 token 位于序列中的哪里。
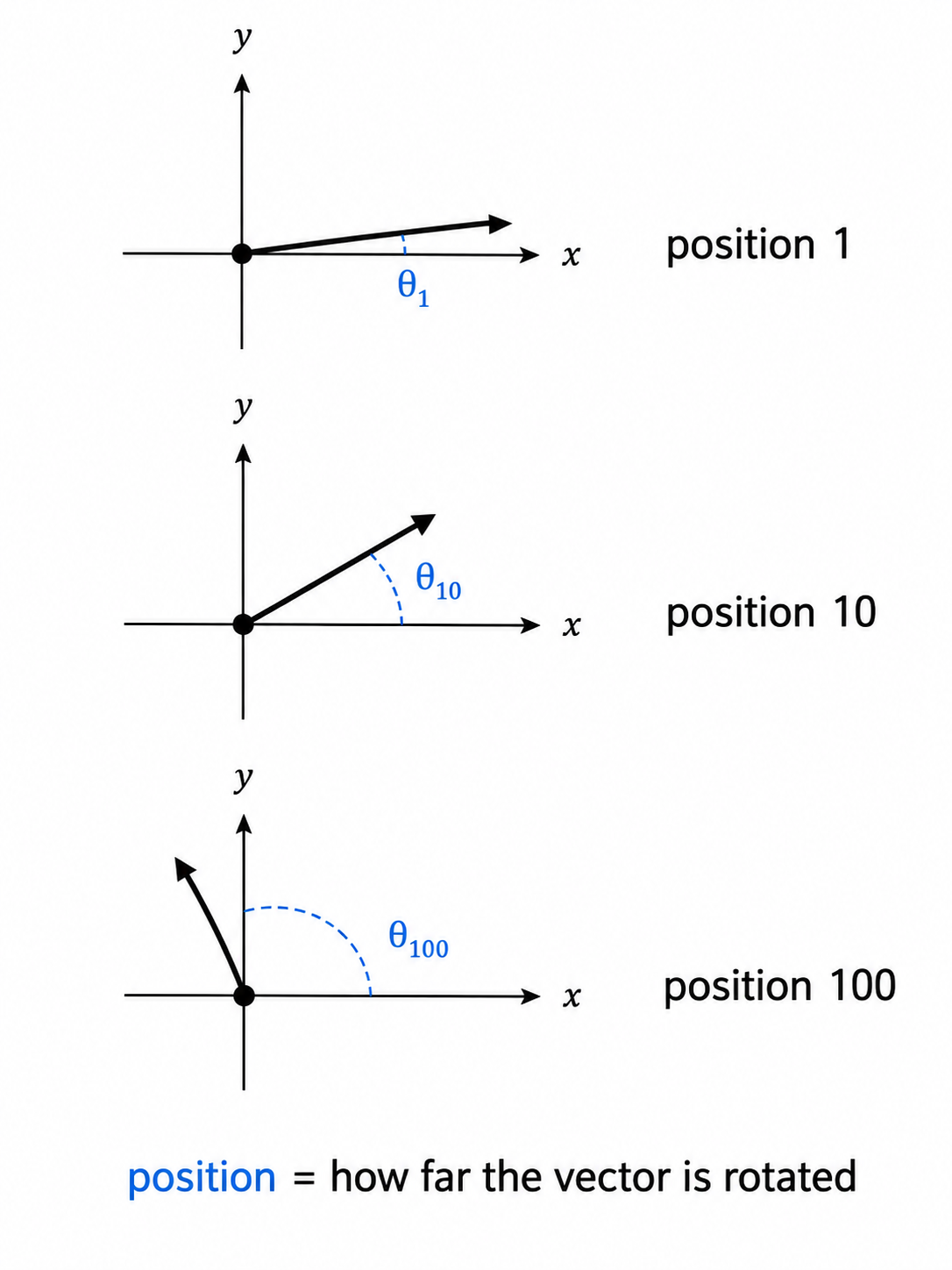
最初的 transformer 论文(Vaswani 等,2017)是这样做的:给每个位置一组自己的数字模式,并在任何其他处理之前,把它直接加到每个 token 的 embedding 上。位置 1 有一种模式,位置 5 有另一种模式,位置 100 又是另一种。这些模式来自不同频率的正弦和余弦波。这样一来,位置 1 的 “dog” 的 embedding 就会不同于位置 5 的 “dog”,只是因为加上去的位置模式不一样。
这套方法是有效的,而选择正弦编码的部分原因,是它可以外推到训练时没见过的精确序列长度之外。但随着模型扩展,加法式位置方案仍然暴露出两个重要问题。
第一,embedding 必须用同一组数字同时承载含义和位置。能塞进去的信息总是有限的。
第二,尤其是学到的绝对位置 embedding,并不能干净地泛化。如果你训练时只见过最多 2,048 个 token 的 prompt,那么模型在训练中从未见过位置 5,000,这个位置的 embedding 也就不是以同样方式学出来的。
现代模型大多使用另一种方案,叫做 Rotary Position Embeddings(RoPE),由 Su 等人在 2021 年提出,现在用于 LLaMA、Mistral、Gemma、Qwen,以及多数其他开放权重模型家族。直觉是:不要把位置信息加到每个 token 的向量上,而是按 token 的位置,用某个角度旋转 Query 和 Key 向量。位置 1 的 token 转一个小角度,位置 100 的 token 转得更大。当两个 token 后续在 attention 中被比较时,重要的是它们 Query 和 Key 旋转之间的差异,这个差异编码了它们相隔多远。
小解释:RoPE
RoPE 是 Rotary Position Embeddings 的缩写。它不添加位置向量,而是旋转 Query 和 Key 向量,让相对距离在 attention 中显现出来。
实际优势很明显。RoPE 天然编码相对位置(这更接近 attention 真正想要的东西)。它对更长上下文的泛化更好。而且它不会给模型增加新的参数。
即使有良好的位置编码,现代 LLM 仍然有一个有文献记录的“lost in the middle”问题(Liu 等,2023)。它们比起埋在长 prompt 中间的信息,更稳定地使用开头和结尾的信息。这就是为什么“把重要上下文放在前面”或“在结尾重复关键信息”这类 prompt 工程技巧真的有帮助。模型并不会同等有效地使用 prompt 的每一部分。
现在 token 的含义和位置都已经编码好了,下一个问题是:token 到底如何交换信息?
Attention
这就是给整个架构命名的机制:attention。
在每个 transformer layer 内部,attention 只做一件事:让每个 token 查看它被允许看到的其他 token,并决定哪些 token 对接下来要发生的事重要。
它的做法是让每个 token 同时扮演三个角色。每个 token 都会被转换成三个新向量,叫做 Query、Key 和 Value(Q、K、V)。
小解释:Q、K、V
Query 表示“我在找什么”,Key 表示“我能匹配什么”,Value 则是在匹配很强时被复制的信息。
- Query 问的是:“我想从其他 token 那里找什么?”
- Key 说的是:“我能给正在看我的 token 提供什么?”
- Value 携带的是:“当匹配发生时,要传递出去的内容是什么?”
同一个 token 会同时扮演这三个角色。Q、K、V 的转换都是学到的矩阵,所以模型会在训练中自己弄明白每个 token 应该寻找什么、又应该提供什么。
匹配通过相似度分数发生。每个 token 的 Query 会与它被允许看到的每个 token 的 Key 比较,使用的是 scaled dot product。直观地说,这衡量两个向量有多对齐。缩放步骤则是在 softmax 之前让数值保持稳定。
小解释:点积
点积是一种简单的打分方式,用来衡量两个向量有多对齐。对齐越高,匹配越强。
这些匹配分数随后通过 softmax 转换成权重。Softmax 会把任意一组数字转换成类似概率的分布,并让它们加起来等于 1。匹配分数更高的 token 会获得更高权重,随后这些权重会用来对 value 向量做加权平均。
小解释:softmax
Softmax 会把原始分数转换成总和为 1 的权重。大分数得到大权重,小分数得到小权重。
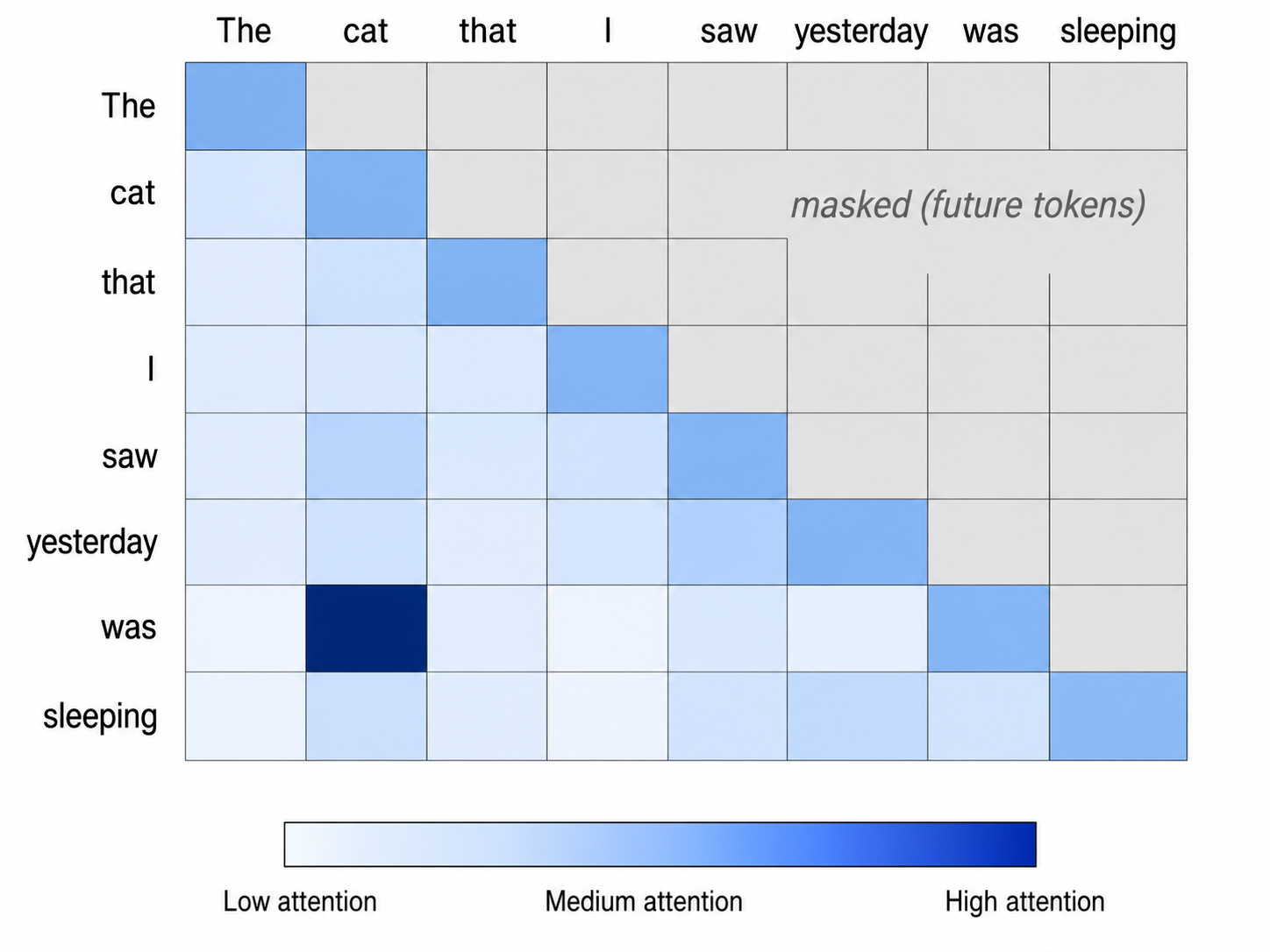
举个例子。考虑句子 “The cat that I saw yesterday was sleeping.” 当模型处理 “was” 时,它需要弄明白是谁在睡觉。“was”的 Query 向量会与它允许看到的 token 的 Key 向量比较。它和 “cat” 的点积很高,因为模型已经学到像 “was” 这样的动词需要主语,而像 “cat” 这样的主语会产生能很好对齐的 Key 向量。它和 “yesterday” 的点积则很低。Softmax 会把这些分数变成权重,“cat” 获得高权重,“yesterday” 获得低权重。然后模型对相应的 value 向量做加权求和,所以 “cat” 的 value 主导了结果。“was”的新表示现在主要由 “cat” 的 value 塑造。这就是一个相隔好几个位置的 token 成为指代对象的方式。
GPT 风格语言模型有一个特定约束:它们从左到右生成文本。位置 5 的 token 只能 attend 到位置 1 到 5。它不能 attend 到位置 6、7、8 的 token,因为那些 token 还没有生成。这叫做 causal masking。实现很简单:未来 token 的匹配分数会被设得极低,以至于 softmax 之后权重实际上为零。
小解释:causal masking
Causal masking 会隐藏未来 token。它防止 decoder-only 语言模型在预测下一个 token 时偷看未来。
可解释性研究里最有趣的发现之一,是 Anthropic 在 2022 年发现的一类专门化 attention head,叫做 induction head。这些 head 会学会识别 prompt 中 “A B … A” 形式的模式,并预测接下来是 B。当模型第二次看到 “A” 时,induction head 会回头找到之前 “A” 出现的位置,看看它后面跟着什么,然后把那个东西复制过来。它们是目前已知最清晰的 in-context learning 机制之一,也就是 LLM 从你的 prompt 中捡起某个模式并继续它的能力。
小解释:induction head
Induction head 是一种 attention head,它会注意 prompt 中重复出现的模式,并帮助模型延续这些模式。
Attention 有一个很大的成本。在完整 attention 中,每个 token 都要和它允许看到的所有 token 比较,所以 prompt 长度翻倍,工作量大致会变成四倍。这就是为什么长 prompt 跑起来昂贵,也解释了为什么很多近期研究都在尝试让 attention 更高效(FlashAttention、sparse attention、linear attention)。
但一个 attention head 只能给模型提供一种对这些关系的学习视角。
Multi-head attention
一次单独的 attention pass 只给模型一种方式,去决定哪些 token 对哪些 token 重要。这还不够。语言里有很多关系在同时发生。主谓一致。代词和它指代的名字。句子之间的长距离引用。词序和局部短语。
Multi-head attention 通过并行运行多次 attention 来解决这个问题,每个并行 pass 都在自己的较小空间中工作。每个并行 pass 叫做一个 head。
小解释:attention head
Attention head 是一次独立的 attention pass,拥有自己的学习投影。
这里有个经常被讲错的地方,很多教程也一样。每个 head 并不是拿到原始 token 向量的一个字面切片。每个 head 都有自己的学习投影矩阵,会把完整 token 向量映射到自己较小的 Q、K、V 向量。因此,如果一个模型每个 token 有 4,096 个数字,并且有 32 个 head,那么每个 head 通常在 128 维空间中工作,但这 128 个数字是从完整的 4,096 维学习投影出来的,而不是固定切下来的片段。它们是同一个 token 的不同“视角”,不是 token 的不同块。
每个 head 会独立运行自己的 attention pass。然后,所有 head 的输出会被拼接起来,并通过最后一个线性层混合回一个完整大小的向量。模型也会学习这个最终混合方式。
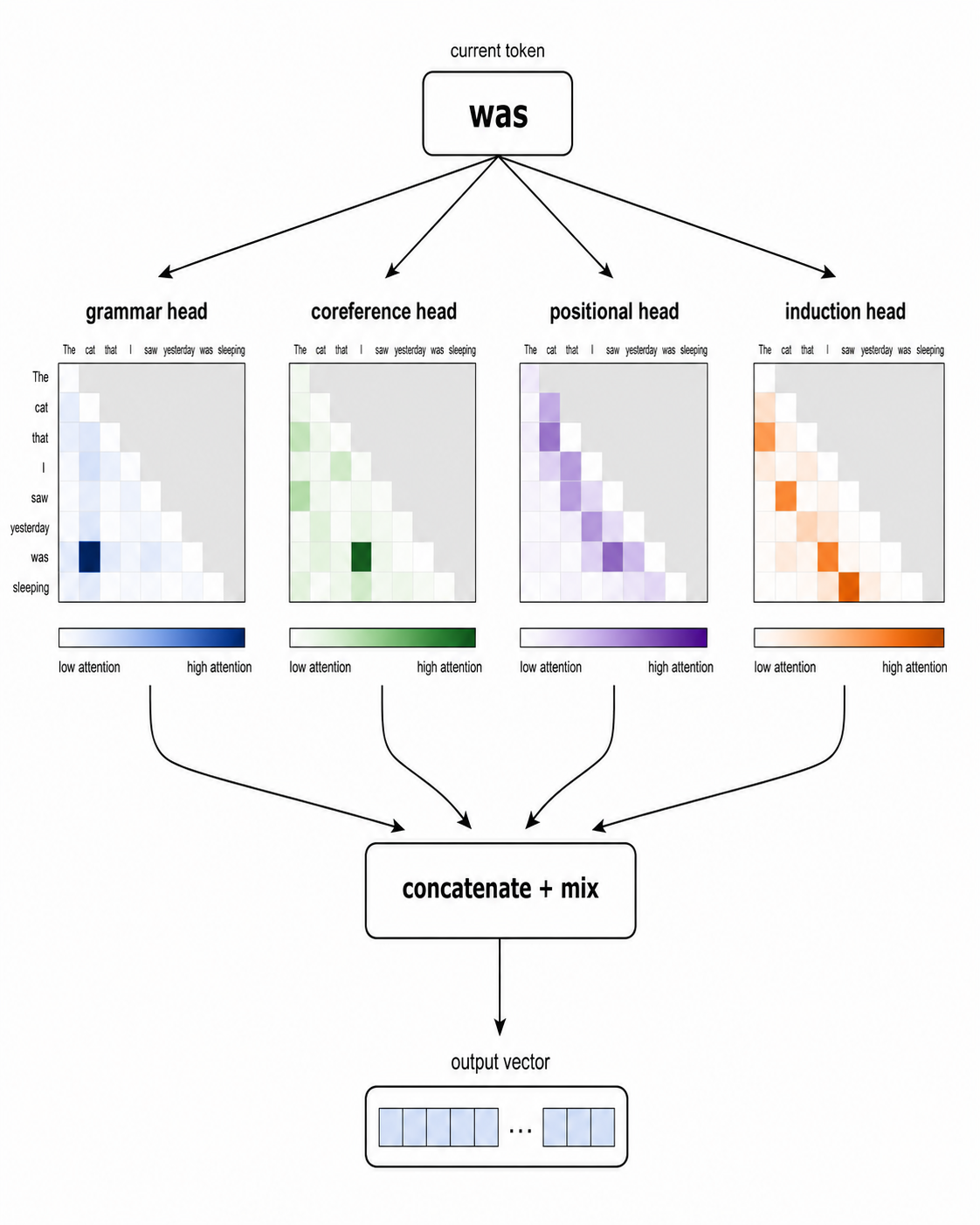
有趣的是,不同 head 往往会变得部分专门化。模型从来没有被告知每个 head 应该做什么。专门化是在训练中自然涌现的。研究者发现过追踪语法的 head(把动词和宾语、冠词和名词连接起来)、判断哪个代词指向哪个名字的 head、追踪位置模式的 head、induction head,以及更多类型。单个 transformer layer 可能有 32 个 head。一个现代前沿模型有几十层。所以典型 LLM 总共会有数千个 attention head,每个都添加自己的学习视角。
这里还有一个实际的成本问题,推动了最近的一项架构变化。每个 head 都需要为所有已经生成的 token 在内存中保存自己的 Key 和 Value 向量,这样当生成新 token 时,模型就不必从头重新计算所有内容。这叫做 KV cache,也是长上下文运行 LLM 时最主要的内存成本。
小解释:KV cache
KV cache 会在生成过程中存储旧的 Key 和 Value 向量。它让模型不用每次添加 token 时都重新计算整个 prompt。
现代 decoder-only LLM 大多使用一种变体,叫做 Grouped-Query Attention(GQA)。不是让每个 head 都拥有自己的 key 和 value,而是让多组 head 共享同一组 key 和 value head。LLaMA-2 70B 有 64 个 query head,但只有 8 个 key/value head。Mistral 7B 有 32 个 query head 和 8 个 key/value head。结果是,精度几乎接近完整 multi-head attention,但内存压力和推理成本低得多。
小解释:GQA
Grouped-Query Attention 让多个 query head 共享更少的 key/value head。这样可以降低 KV-cache 内存,同时保留许多 query 视角。
Feed-forward network
Attention 完成 token 之间的信息混合之后,每一层还有第二个步骤,只是大家谈得没那么多:feed-forward network。
如果说 attention 关心的是 token 彼此交谈,那么 feed-forward network 关心的就是每个 token 独自做进一步处理。它独立运行在每个 token 的向量上,不发生跨 token 混合。
Feed-forward network 依次做三件事:
- 把 token 的向量扩展到更大的尺寸(原始 transformer 使用 4 倍扩展,而现代 SwiGLU 模型常常使用不同的扩展大小)。
- 应用一个非线性函数。
- 再把向量压缩回原来的大小。
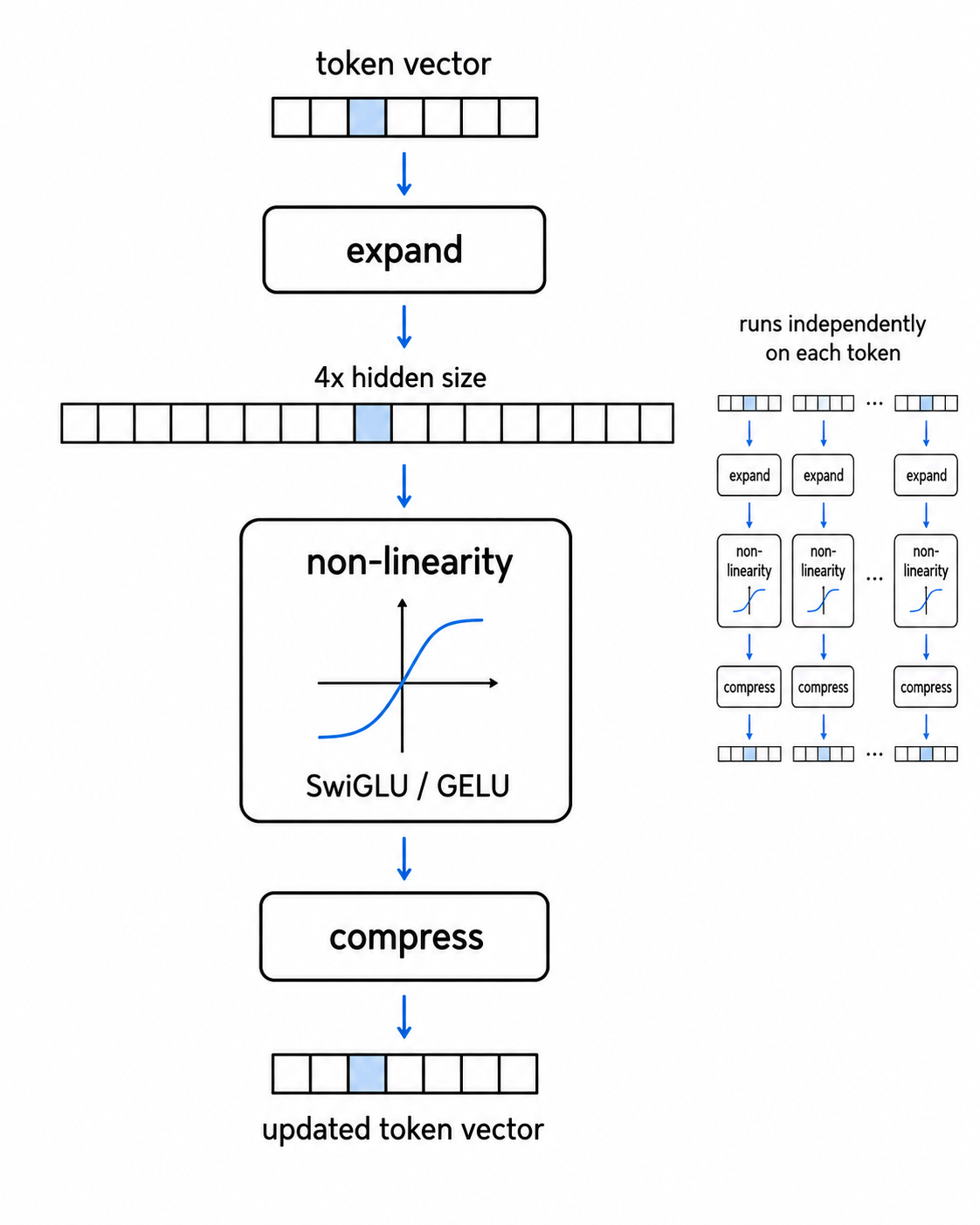
中间这个非线性步骤在做的事情很值得理解。非线性函数会“弯曲”它的输入。最简单的一种 ReLU,会把任何负数输出为零,而正数则原样通过。
小解释:非线性
非线性是一种函数,它防止网络坍缩成一个巨大的线性变换。
没有它,FFN 就只是两个线性层堆在一起,而纯线性数学的堆叠会坍缩。连续两个线性层在数学上等价于一个线性层,连续一百个线性层仍然等价于一个。非线性阻止了这种坍缩,这也是 FFN 能做出比单个矩阵乘法更丰富事情的原因。
原始 transformer 使用 ReLU。GPT 和 BERT 转向 GELU。像 LLaMA、Mistral 和 PaLM 这样的现代模型使用 SwiGLU。扩展再压缩的结构保留了下来,被持续迭代的是非线性本身。
在 dense transformer 模型中,大部分参数位于 FFN,而不是 attention。相当大一部分权重都在 feed-forward 层里。
这些参数也不是泛泛而谈的东西。模型中许多已存储的事实和语义结构都在这里。研究者发现,FFN 内部的一些神经元会与特定概念或事实强相关。某个神经元可能会在与埃菲尔铁塔有关的文本上强烈激活。另一个可能针对编程语言。另一个可能针对过去式动词。当一个模型“知道”巴黎是法国首都时,这个事实会以跨越特定层中 FFN 权重和激活的方式被表示出来。
这种存储记忆的性质有一个有趣后果。研究者已经找到了在不重新训练模型的情况下,直接编辑训练好模型中某些事实的方法。像 ROME(Rank-One Model Editing)这样的方法,可以通过对某个特定 FFN 权重矩阵做一次有针对性的低秩编辑,把“埃菲尔铁塔在巴黎”改成“埃菲尔铁塔在罗马”。之后模型通常就会生成与这个被编辑关联一致的文本。
一些现代前沿模型已经开始用一种叫做 Mixture of Experts(MoE)的东西替换 dense FFN。不是每层只有一个 feed-forward network,而是有很多并行 FFN(称为 experts),再由一个很小的 router network 决定每个 token 由哪些 expert 处理。Mixtral 8x7B 每层有 8 个 expert;对任意给定 token,只激活其中 2 个。总参数量会显著增加,但每个 token 的计算量增长慢得多,因为只有少数 expert 会运行。这就是在不按比例增加推理成本的前提下扩展参数量的方法。
小解释:MoE
Mixture of Experts 意味着模型有多个 feed-forward network,并且只把每个 token 路由到其中少数几个。
Mixtral 8x7B 总共有 46.7B 参数,但每个 token 只使用大约 12.9B 参数。它已经成为超大模型的一种常见选择,因为它允许你持续增加参数量,而不用让推理成本按同等比例增长。
Residual stream and layer normalization
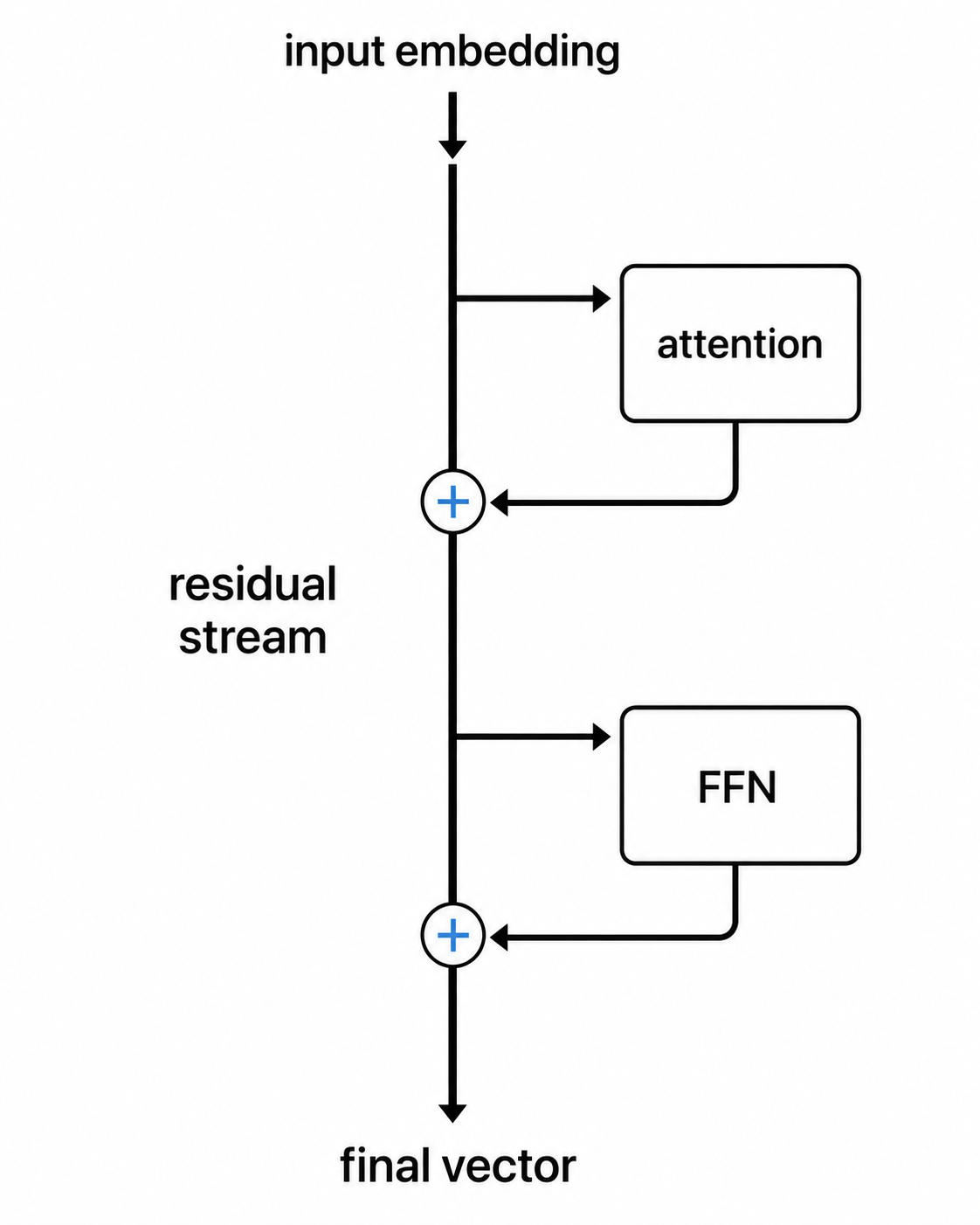
Residual stream 让模型变成“叠加式”的,而不是“替换式”的。Attention 运行之后,或者 feed-forward network 运行之后,结果通常不会替换 token 的向量。它会被加回去,逐位置相加。新向量等于旧向量加上子模块的输出。
小解释:残差连接
残差连接会把一个模块的输出加回它开始时的向量。它为信息和梯度提供了一条穿过网络的捷径。
跨越三十层、五十层或一百层时,每一层的贡献会累积,而不是简单覆盖前一个向量。这个运行中的总和叫做 residual stream,并且它有一个奇特性质:原始输入 embedding 仍然有一条直接的加法路径通向后面的层,沿途还混合了每个子模块的贡献。
残差连接并不是为 transformer 发明的。它来自 ResNet(He 等,2015),最初用于图像识别。动机是深度网络当时很难训练。训练信号穿过许多层反向传播回来时会变得太弱(有时也会太强)。模型实际上无法从自己的错误中学习。添加一条捷径之后,信号就能从输出直接流回输入。突然之间,人们就可以训练数百层的网络了。Transformer 继承了同样的技巧。
在现代可解释性研究中,residual stream 已经成了中心对象。每个组件、每个 attention head、每个 feed-forward network,甚至最后的 unembedding 步骤,都会从 residual stream 读取并写回到它。
第二块是 layer normalization,它存在的原因就实用得多。没有它,residual stream 无法保持稳定。穿过几十次加法流动的数字,往往要么向上爆炸,要么塌缩到零附近。不管哪一种,训练都会失败。Layer normalization 会在子模块之间,把每个 token 的向量重新缩放回一个受控范围。
小解释:layer normalization
Layer normalization 会重新缩放 token 向量,让它的数字在模型训练时保持在稳定范围内。
最初的 2017 transformer 会在每个子模块之后应用 normalization(post-norm)。这对浅层模型可行,但随着深度增加,可靠训练会变得更困难。现代 transformer(从 GPT-2 开始,以及 LLaMA、Mistral)通常会在每个子模块之前应用 normalization(pre-norm)。这是让很深的 transformer 更容易训练的变化之一。
函数本身也发生了变化。许多现代开放模型(LLaMA、Mistral、Gemma、Phi)使用一种更简单的变体,叫做 RMSNorm。原始 layer normalization 同时做两件事:把每个向量向零平移,然后重新缩放数字大小。RMSNorm 去掉了平移步骤,只保留重新缩放。经验上,重新缩放贡献了大部分收益,而且计算更便宜。
小解释:RMSNorm
RMSNorm 是一种更便宜的 normalization 方法,它不先减去均值,只重新缩放向量大小。
所以这就是那些不太光鲜的机械结构。没有残差连接,很深的模型会难训练得多。没有 layer normalization,运行中的总和可能爆炸或塌缩。有了二者,你才能得到数百层深的模型。
Next-token prediction
所有层的 attention 和 feed-forward 处理结束之后,模型会为序列中的每个 token 得到一个向量。在生成时,为了预测下一个词,它只取最后一个 token 的最终向量。
这个最后的向量会被转换成每个可能下一个 token 对应的一个数字。如果词表有 100,000 个 token,那就是 100,000 个数字。这些数字叫做 logits。它们还不是概率。它们可以是任意大小,可以为正也可以为负。
小解释:logits
Logits 是每个可能下一个 token 的原始分数。只有经过 softmax 之后,它们才会变成概率。
Softmax 会把这些 logits 转换成模型对可能下一个 token 的概率分布。和前面同一个操作,只是用在模型中的不同位置。
模型通常不会每次都只选择概率最高的 token。Decoding 设置会控制输出有多确定或多变化。Temperature 会改变分布的尖锐程度。Top-k 和 top-p 会把选择限制在最可能的一批下一个 token 中。这就是为什么同一个模型在一种设置下显得精确,而在另一种设置下显得更有创造力。
小解释:temperature
Temperature 控制采样时的随机性。低 temperature 会让模型更保守;高 temperature 会让模型更多变。
一旦选中一个 token,它就会被添加到输入中。模型在更长的序列上运行下一步,通常会复用 KV cache,这样就不必从头重新计算整个前缀。新 token 的新 attention。新的 feed-forward。新的最终向量。新的预测。这个循环会一直继续,直到模型输出 end-of-sequence token,或者达到长度限制。整整一段文字,说到底就是这个循环一次生成一个 token。
这种单一目标,也就是预测下一个 token,是 base LLM 的核心训练信号。Base model 并不是直接为了事实准确性、对话能力、推理或写代码而训练的。它是在海量文本上训练,去预测下一个 token。之后的后训练,才会进一步把模型调成更擅长遵循指令、满足偏好、安全控制和对话行为。
这里有一个值得了解的重要效率创新,叫做 speculative decoding。一个小而快的模型会先往前提议几个 token。大模型再并行验证它们。如果提议的 token 在大模型的概率下被接受,就接受它们。如果不接受,就退回大模型。只要做得正确,输出分布会和单独运行大模型一致,但这个循环能跑得快得多。
小解释:speculative decoding
Speculative decoding 使用一个小的 draft model 先向前猜测,然后让更大的模型一次性验证多个猜到的 token。
下一个 token 预测循环是架构中最简单的部分,但它让整个系统真正运转起来。
Architecture vs trained weights
我们已经走过了核心机制:token、embedding、位置编码、attention、multi-head attention、feed-forward network、residual stream 和 normalization,以及输出侧的下一个 token 循环。这就是基本架构的一次完整巡游。
那么 GPT、Claude、Gemini 和 LLaMA 之间到底有什么不同?公开细节各不相同,专有模型也不会发布所有架构选择。但在这篇文章讨论的层次上,它们大体都位于同一个 transformer 家族设计空间里。
大多数现代基于 transformer 的 LLM 使用同样的大结构:tokenization、embedding、位置编码、堆叠的 transformer 层(每层包含 multi-head attention 和 feed-forward network)、residual stream、layer normalization,以及下一个 token 预测。
模型之间变化的是:
- 训练好的权重本身,也就是从不同训练数据、不同规模中学到的东西。
- 配置:层数、词表大小、head 数量、参数量、MoE 或 dense。
- 后训练:指令微调、从人类反馈中学习、叠加在 base model 之上的安全控制。
小解释:权重
权重是模型内部学到的数字。训练会改变这些数字,直到模型能很好地预测文本。
2023 到 2025 年的“现代 transformer”栈,在许多严肃的前沿模型和开放权重模型之间收敛到了一组常见选择,哪怕不同团队是独立走到这里的。Pre-norm 布置。RMSNorm。RoPE。SwiGLU。Grouped-Query Attention。一些最大模型中的 Mixture of Experts。这些东西并不是一次性被发明出来的。它们是在原始 2017 设计之上,经过大约五年细化慢慢积累起来的。
Where this is going
围绕 transformer 家族架构形成这种收敛,在机器学习历史上并不寻常。在这个领域的大部分时间里,每个问题都有自己专门的网络。图像识别用一种。语言用另一种。音频用第三种。视觉团队和语言团队几乎不共享方法。
现在,transformer 风格的模型出现在语言、视觉、音频和多模态系统中。Transformer 吸收了这个领域的一大部分。
这也可能改变。Mamba 和其他 state-space model 是可信的替代方案,尤其适合非常长的序列。Hybrid architecture 也正在被探索。Mixture-of-experts 已经改变了前沿模型里“架构”这个词的含义,而这种变化在五年前还会被视为相当奇特。
但这篇文章里的核心机制(token、embedding、位置编码、attention、feed-forward network、residual stream 和 normalization,以及下一个 token 预测)是持久的部分。即使架构发生变化,这些仍然是任何序列模型都必须以某种形式解决的问题。
如果你读到了这里,你已经可以阅读许多现代 transformer 论文或模型卡,并知道每一节在谈哪一块了。这就是目标。
非常欢迎反馈。如果你对这些内容感兴趣,请在 X 上联系我。我喜欢认识新朋友。
非常欢迎反馈。如果你对这些内容感兴趣,请在 X 上联系我。我喜欢认识新朋友。