有一种新方法可以:
- 将语料库规模缩小 40 倍。
- 将每次查询的 token 数减少 3 倍。
- 将向量搜索相关性提升 2.3 倍。
而且它不需要改动你的检索算法、重排序器或 embedding 模型。它修复的是一个几乎没人检查的上游问题。
每条 RAG 流水线都从同一个假设开始:一段文本 chunk 是适合被嵌入的知识单元。
这个假设几乎从未被认真审视。
而它正是许多人试图在下游修补的大多数检索失败的根源。
为什么 chunk 不是好单元
文本 chunk 是一种结构中立的容器。它不知道:
- 其中的想法从哪里开始、在哪里结束
- 它来自文档的哪个版本
- 谁被允许查看它
由于 chunk 没有想法边界,切分器只能在 token 数用完的地方下刀。

最后你检索到的可能是半张表、没有论证过程的结论,或者一个被剥离了成立语境的断言。模型没有办法知道缺了什么。
版本问题同样严重。
大多数企业语料库里,同一份文档会以十几个几乎相同的版本散落在 SharePoint、Confluence 和 Git 中。
Top-K 检索会返回同一段落的五个副本,其中既有当前版本,也有废弃版本。LLM 会把它们混合成一个自信但错误的答案。
因为 chunk 本身也不携带元数据,访问控制就没有地方附着在数据自身上。
角色过滤、版本状态、权限等级:所有这些最终都会变成挂在 orchestrator 上的逻辑,和它本应治理的内容脱节。
LangChain、LlamaIndex 和 Haystack 都位于这一层之上。它们只是编排你放进向量库里的内容的检索。
大多数技术栈在文档解析器和向量库之间什么也没有。
这道空隙,正是这三个问题叠加放大的地方。
更好的单元:问答包
chunk 之所以失败,是因为它在结构上不可知。修复方式是让知识单元在结构上显式化。
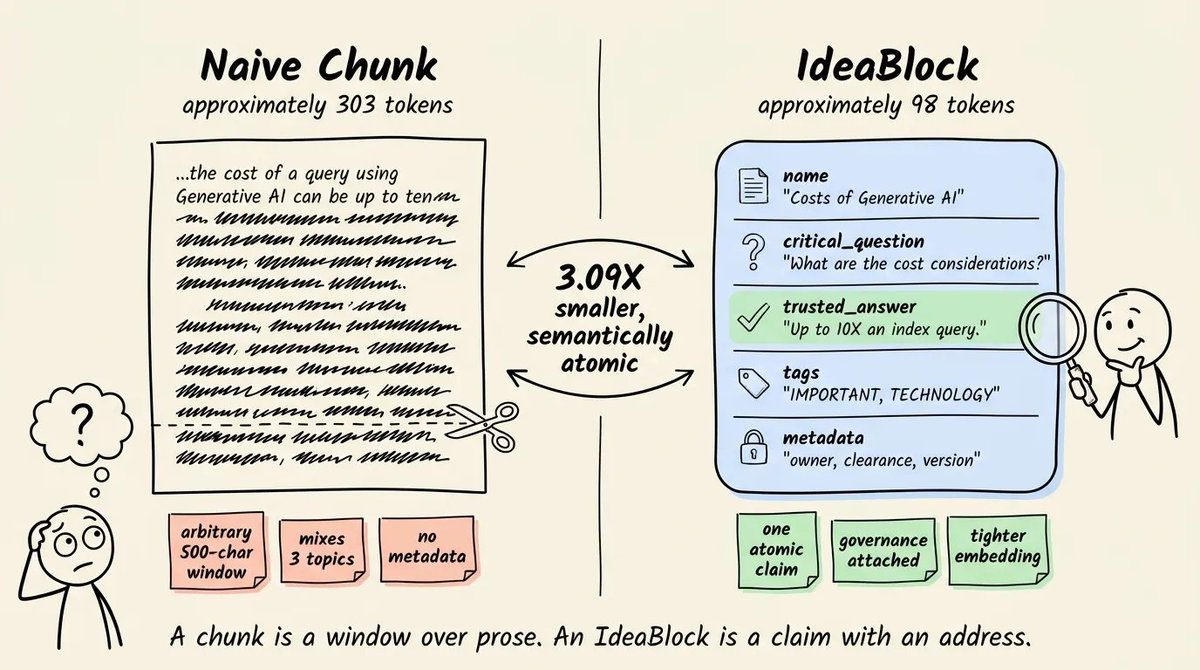
不要嵌入一段散文窗口,而是嵌入一个断言:一个问题、它经过验证的答案,以及以类型化 schema 表示的治理字段。
每个单元只承载一个事实,仅此而已。
你的查询本来就是问题。当索引存储的是问题的答案时,匹配就变成了结构性的,而不只是语义性的。
你不再只是希望正确段落浮到最前面。你是在把问题直接匹配到它的答案。
Blockify 是 Iternal Technologies 的一个预处理层,它把这种结构实现为所谓的 IdeaBlock:一个问题、它经过验证的答案,以及权限等级、版本状态、来源等类型化治理字段,全部放在同一个对象上。
它镜像了用户实际查询 RAG 系统的方式:以问题的形式查询。
关键洞察是:当你嵌入的是问答包,而不是文本窗口时,你的 embedding 表示的是一个单一的原子断言,而不是一段碰巧包含该断言的叙事文本。
这会在向量几何上产生可测量的后果。
在 Blockify 覆盖 17 份文档、298 页内容的内部基准测试中,从查询到最佳匹配 block 的平均余弦距离,IdeaBlock 为 0.1585,而朴素 chunk 为 0.3624。
这意味着检索距离降低了 2.29 倍。
反直觉发现:数据更少,准确率更高
大多数人会以为,缩小语料库会损害检索效果。
但语义蒸馏并不会这样。
在 Blockify 的内部基准测试中,流水线从源文档中生成了 2,042 个原始 IdeaBlock。

经过 3 到 5 轮、相似度阈值为 80-85% 的迭代去重后:
- 2,042 个 block 合并为 1,200 个规范化 IdeaBlock
- 词数从 88,877 降到 44,537
- 蒸馏后的数据集在向量准确率上比未蒸馏版本高 13.55%
冗余副本之所以会伤害结果,而不是帮助结果,是因为同一段落的十五个近似副本会在 embedding 空间的同一区域制造十五个相互竞争的向量。
检索会把概率质量分散到它们所有副本上,拉低规范版本的匹配分数。把它们折叠成一个规范 block 后,信号会变得更清晰。
你的向量索引不是一块需要塞满的硬盘。它是一个检索表面,而冗余会劣化这个表面。
流水线:从文档到 IdeaBlock
修复方式是在任何内容进入向量库之前,先运行一条预处理流水线。
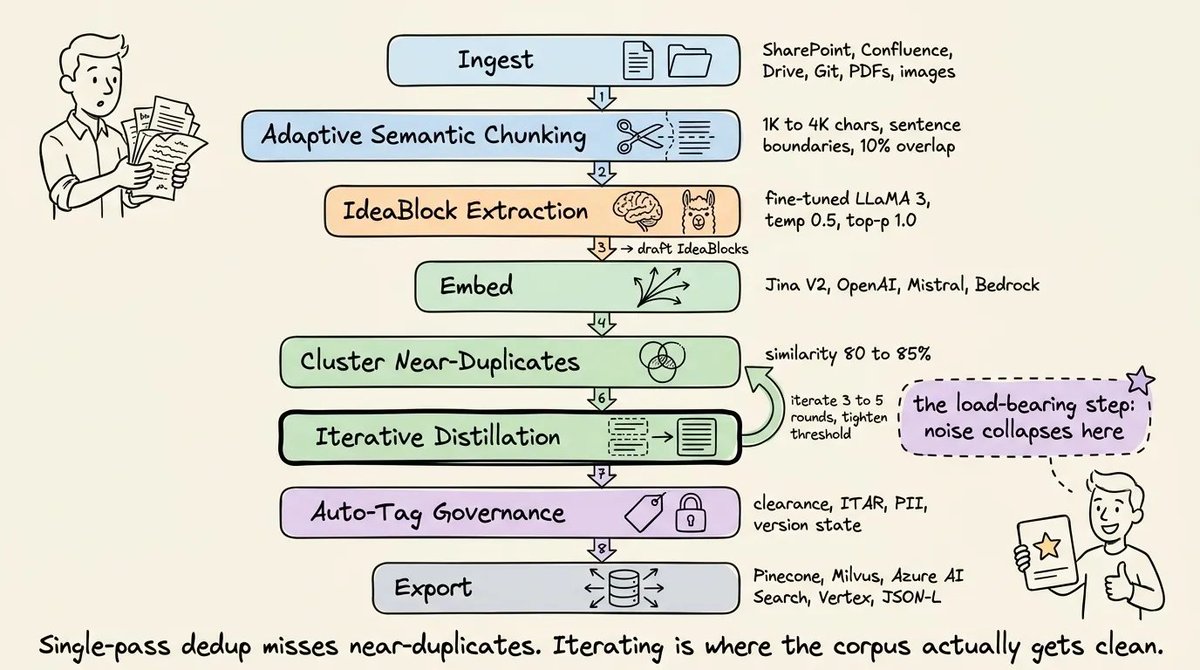
Blockify 的处理分为七个阶段。每个阶段都有明确的输入和输出,因此故障可以被定位,也可以被复现。
阶段 1:范围界定
在解析任何文档之前,你需要定义索引层级:组织 > 业务单元 > 产品 > 用户画像。
这会决定哪些 block 被标记到哪些访问层级,也会影响后续去重的方式。
阶段 2:摄取
文档可以以 DOCX、PDF、PPT、PNG/JPG、Markdown 或 HTML 的形式进入。
解析器会把内容交给 LLM 层,运行微调过的 LLaMA 3 / QWEN 3.5 / Gemma4(以及其他自定义基础模型变体),把原始 chunk 转换为草稿 IdeaBlock:一个关键问题、一个两到三句话的已验证答案,以及类型化治理字段。
输入大小限制在 1,000 到 4,000 个字符之间,2,000 个字符是实践中的中间值。
阶段 3:切分与抽取
上下文感知切分意味着,LLM 会把 chunk 转换成草稿 IdeaBlock,而不是只按 token 数截断。每个 chunk 的输出都是一个问答对,而不是一个散文窗口。
阶段 4:语义去重
这里是清理检索表面的地方。
block 会按 80-85% 的余弦相似度阈值进行聚类,并迭代三到五轮。
近似重复项会通过第二个专门调优过的 LLM 合并成单一规范 block。这条流水线为 GPU 优化,但也可以通过 Intel Xeon 优化版本利用额外的 CPU 容量运行。
结果是,索引中的每个向量都代表一个独立断言,而不是十五个互相竞争、几乎相同的副本之一。
阶段 5:自动标注
每个 block 都会获得类型化元数据:权限等级(PUBLIC、INTERNAL、CONFIDENTIAL、SECRET)、版本状态(Current、Deprecated、Draft、Approved)、产品线、出口管制标记,以及数据隐私标签。这些由流水线施加,而不是由文档作者施加。
阶段 6:人工验证
一个包含 2,000 到 3,000 个 IdeaBlock 的产品语料库,可以分给 5 到 10 位 SME,每人每季度花 1 到 2 小时处理自己的部分。验证对象是附带来源引用的结构化断言,而不是原始文档。
阶段 7:导出
经过验证的 block 会通过 API 推送到向量数据库,或导出为 JSON-L。支持的向量库包括:Azure AI Search、Pinecone、Milvus、Vertex Matching Engine。支持的 embedding 模型包括:OpenAI、Bedrock、Mistral、Jina 以及开源模型。
无论你使用哪种组合,这条流水线都位于文档解析器和向量库之间。
应用层会发生什么变化
你嵌入的单元决定了应用层能做什么。

- 查询构造变得更简单:你的查询本来就是问题。当索引存储的是问题的答案时,匹配就是结构性的,而不是概率性的。你不再需要调整相似度阈值,去补偿查询形状和文档形状之间的语义错位。
- 治理进入数据层:基于角色的访问、版本状态、权限等级都是每个 block 上的类型化字段,而不是挂在 orchestrator 上的逻辑。销售工程师和法务审核员查询同一个索引时,会得到不同的数据集;不是因为检索层进行了过滤,而是因为 block 自身携带了访问边界。
- 更新从单条记录传播:当规格发生变化时,你只需要更新一个 IdeaBlock。所有查询这个 block 的应用都会在下一次请求中得到修正后的答案。用朴素 chunking 时,同一个事实会存在于多份文档的几十段近似重复内容里。更新它意味着找到所有副本,而这在企业规模下并不可行。
架构不会改变你如何查询。它改变的是你可以对答案信任到什么程度。
底层原则
chunk 原本只是解析上的便利,却变成了检索上的假设。
它没有想法边界、版本上下文或访问状态。多年来,检索栈一直在修补这种错配:重排序器、混合搜索、阈值调优、提示词工程。
所有这些都发生在真正问题的下游。
修复方式不是更好的检索算法,而是更好的单元。
RAG 技术栈正在开始在解析和向量化之间长出一层蒸馏层,就像 Web 技术栈曾经在源站和浏览器之间长出 CDN 层一样。
你可以用聚类、基于 LLM 的摘要和 schema 约束自己构建这一层。或者,你也可以使用像 Blockify 这样为此专门打造的工具。
无论哪种方式,把 chunk 当作知识单元的假设才是 bug;在数据层修复它,比继续调检索参数更有回报。
它是开源的!
感谢阅读!
如果你觉得有启发,欢迎转发给你的网络。
找我 → @akshay_pachaar ✔️
获取更多关于 LLM、AI Agent 和机器学习的见解与教程!