我们 99% 的生产代码都是 AI 写的。上周二上午 10 点,我们上线了一个新功能,中午做了 A/B 测试,下午 3 点因为数据不行就下线了。下午 5 点我们又上线了一个更好的版本。三个月前,这样一个循环要花六周。
我们不是靠在 IDE 里加个 Copilot 走到今天的。我们把整个工程流程拆掉,围绕 AI 重新搭建。我们改了怎么规划、怎么开发、怎么测试、怎么部署、怎么组织团队。我们也改了公司里每个人的角色。
CREAO 是一个 agent 平台。公司 25 个人,工程师 10 个。我们从 2025 年 11 月开始做 agents,两个月前我把整个产品架构和工程工作流从底层重构了一遍。
OpenAI 在 2026 年 2 月提出了一个概念,刚好概括了我们当时在做的事。他们叫它 harness engineering:工程团队的首要工作不再是写代码,而是让 agents 能做有用的工作。系统出问题时,答案永远不是“再努力一点”,而是:缺了什么能力?怎么把它变成 agent 可理解、可执行、可约束的机制?
我们是自己走到这个结论的。只是当时还没有名字。
AI-First 和“使用 AI”不是一回事

大多数公司只是把 AI 贴到现有流程上。工程师打开 Cursor,PM 用 ChatGPT 写规格,QA 试试 AI 生成测试。流程本身不变,效率提升 10% 到 20%,但结构没有变化。
这叫 AI-assisted。
AI-first 的意思是:你默认 AI 是主要建设者,然后反过来重设计流程、架构和组织。你不再问“AI 怎么帮工程师”,而是问“我们要怎么把整套系统改造到让 AI 来建设,工程师负责方向和判断”。
这两者的差距是乘法级别的。
我看到很多团队自称 AI-first,但还是同样的 sprint 节奏、同样的 Jira 看板、同样的周会站会、同样的 QA 签字流程。他们只是把 AI 加进了循环,没有重设计循环本身。
常见的一种就是所谓 vibe coding:打开 Cursor,不断 prompt 到“能跑”为止,提交,重复。它能做出原型,但生产系统需要稳定、可靠、安全。你需要一套在“AI 写代码”前提下仍然保证这些属性的系统。系统才是核心,prompt 是一次性的。
为什么我们必须改变
去年我观察团队工作方式时,看到了三个会把我们拖死的瓶颈。
产品管理瓶颈
我们的 PM 要花几周做调研、设计、写规格。这个模式用了几十年。但 agent 两小时就能做完一个功能。构建时间从“按月”坍缩到“按小时”后,几周的规划周期反而成了约束。
你不可能先想几个月,再两小时做完。
PM 必须进化成以产品为导向的架构师,能跟上高频迭代;否则就要退出构建主循环。设计要通过“快速原型-上线-测试-迭代”完成,而不是在评审会上反复审文档。
QA 瓶颈
同样的问题。agent 发完功能后,我们 QA 团队要花几天测边界场景。开发两小时,测试三天。
我们用 AI 搭了测试平台,去测试 AI 写的代码。验证速度必须跟实现速度同级,否则你只是把旧瓶颈往下游挪了十英尺。
人力规模瓶颈
我们的竞争对手做同类工作时,人数是我们的 100 倍甚至更多。我们一共 25 个人,不可能靠招人追平,只能靠重设计追平。
有三套系统必须全链路 AI 化:产品怎么设计、产品怎么实现、产品怎么测试。任何一环还是手工,整个流水线都会被它卡死。
大胆决定:统一架构
我先修代码库。
旧架构分散在多个独立系统里。一个改动经常要动三四个仓库。对人类工程师来说还能管理,对 AI agent 来说是黑盒。它看不到全局,推不出跨服务影响,也没法本地跑集成测试。
所以我必须把代码统一进一个 monorepo。一个关键原因就是:让 AI 看见全貌。
这正是 harness engineering 的实践原则。你把系统越多部分变成 agent 可检查、可验证、可修改的形态,杠杆就越大。碎片化代码库对 agents 是不可见的,统一代码库才是可读的。
我先花一周设计新系统:规划阶段、实现阶段、测试阶段、集成测试阶段。再花一周用 agents 把整套代码重构完。
CREAO 本身是 agent 平台。我们用自己的 agents 重建了运行 agents 的平台。如果产品能“自建”,说明它有效。
技术栈
这是我们的栈,以及每一层在做什么。
基础设施:AWS
我们跑在 AWS 上,容器服务自动扩缩容,并有 circuit-breaker 回滚。部署后只要指标退化,系统会自动回滚。
CloudWatch 是中枢神经。所有服务结构化日志、25+ 告警、自动化工作流每天查询自定义指标。每一层基础设施都暴露结构化、可查询信号。AI 看不懂日志,就不可能诊断问题。
CI/CD:GitHub Actions
每次代码变更都走六阶段流水线:
Verify CI → Build and Deploy Dev → Test Dev → Deploy Prod → Test Prod → Release
每个 PR 的 CI 闸门强制执行类型检查、lint、单元和集成测试、Docker 构建、Playwright 端到端测试、环境一致性检查。没有可选项,没有人工跳过。流水线是确定性的,agent 才能预测结果并定位失败原因。
AI 代码审查:Claude
每个 PR 都会触发三路并行的 Claude Opus 4.6 审查:
Pass 1:代码质量。逻辑错误、性能问题、可维护性。
Pass 2:安全。漏洞扫描、鉴权边界检查、注入风险。
Pass 3:依赖扫描。供应链风险、版本冲突、许可证问题。
这些是审查闸门,不是“建议”。它们和人工审查并行,能规模化补上人眼漏掉的部分。你一天发八次版时,没有任何人类 reviewer 能对每个 PR 长时间保持同等注意力。
工程师也会在 GitHub issue 或 PR 里 @claude,让它做实现方案、debug 会话或代码分析。agent 能看到整个 monorepo,上下文能跨对话延续。
自愈反馈回路
这是核心。
每天 UTC 9:00,自动健康检查工作流运行。Claude Sonnet 4.6 查询 CloudWatch,分析全服务错误模式,生成管理层健康摘要并发到 Microsoft Teams,全程无需人工触发。
一小时后,分诊引擎启动。它聚类 CloudWatch 和 Sentry 的生产错误,按九个严重性维度打分,并在 Linear 自动创建调查工单。每张工单都附带样例日志、受影响用户、受影响接口、建议排查路径。
系统会自动去重。如果已有 open issue 覆盖同一错误模式,就更新该 issue;如果一个已关闭 issue 再次出现,它会识别为回归并自动重开。
工程师提交修复后,还是同一条流水线。三轮 Claude 审查 PR,CI 校验,通过六阶段发布链路推进 dev 和 prod,并在每一阶段测试。部署后,分诊引擎再次检查 CloudWatch。原始错误若已消失,Linear 工单自动关闭。

每个工具只负责一个阶段,没有工具试图包打天下。这个日循环形成了自愈闭环:检测错误、分诊、修复、验证,人工干预降到最低。
我对 Business Insider 的记者说过:“AI 会把 PR 做出来,人只需要审是否有风险。”
Feature Flags 与配套栈
Statsig 负责 feature flag。每个功能都在开关后发布。发布模式是:先团队内开,再按比例灰度,再全量或下线。下线开关可瞬时关闭功能,不需要重新部署。指标一旦退化,我们几小时内就撤回。坏功能在上线当天就会被干掉。A/B 测试也走同一系统。
Graphite 管理 PR 分支:merge queue 先 rebase 到 main,再重跑 CI,绿灯才合并。Stacked PR 支持高吞吐下的增量评审。
Sentry 负责汇总全服务结构化异常,分诊引擎再和 CloudWatch 合并做跨工具上下文。Linear 是人类操作层:自动建单、严重性评分、样例日志、调查建议。去重机制防噪音,修复后的复检会自动关单。
一个功能如何从想法走到生产
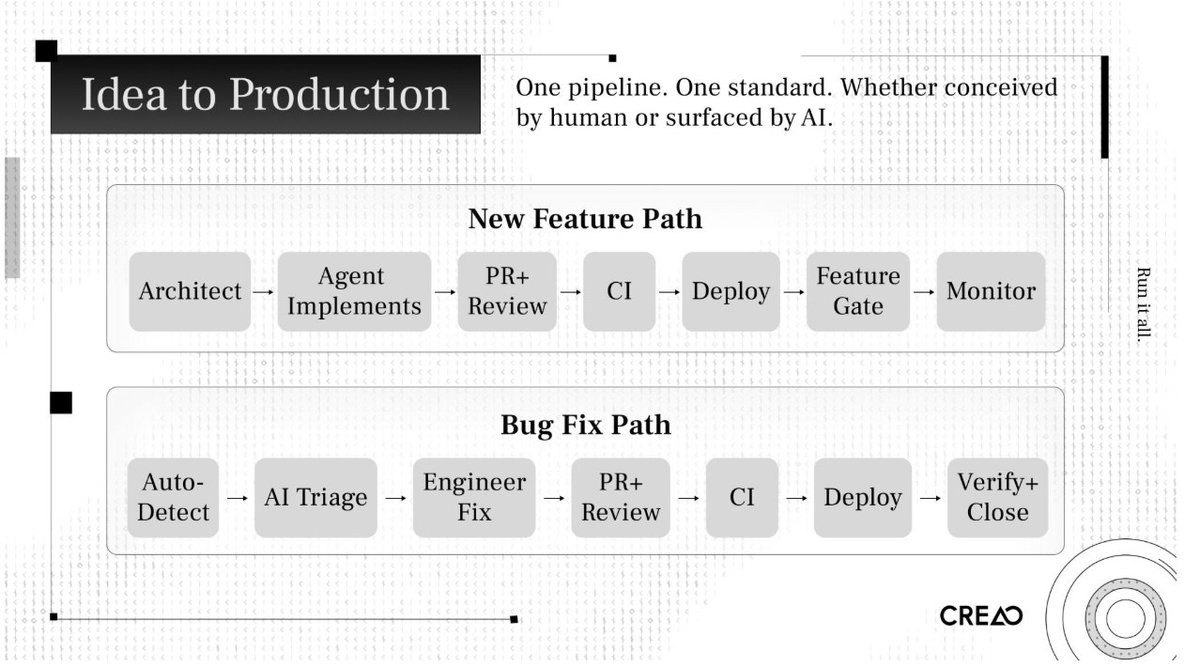
新功能路径
- 架构师把任务定义成结构化 prompt,包含代码库上下文、目标和约束。
- agent 拆解任务、制定实现计划、写代码并生成测试。
- PR 打开后进入三轮 Claude 审查。人工 reviewer 只看战略层风险,而不是逐行验算。
- CI 校验:类型检查、lint、单测、集成测试、端到端测试。
- Graphite 的 merge queue 会 rebase、重跑 CI,绿灯合并。
- 六阶段发布流水线在 dev 与 prod 分阶段推进,每阶段都测试。
- 先给团队开启 feature gate,再逐步按比例放量,并持续监控指标。
- 若有退化,随时用 kill switch 关闭;严重情况由 circuit-breaker 自动回滚。
Bug 修复路径
- CloudWatch 与 Sentry 发现错误。
- Claude 分诊引擎打严重性分,自动在 Linear 创建带完整调查上下文的 issue。
- 工程师介入调查,AI 已经先完成诊断;工程师负责验证并提交修复。
- 仍然走同样的审查、CI、部署与监控流程。
- 分诊引擎复检,问题解决后自动关单。
两条路径共用同一流水线。一个系统,一套标准。
结果
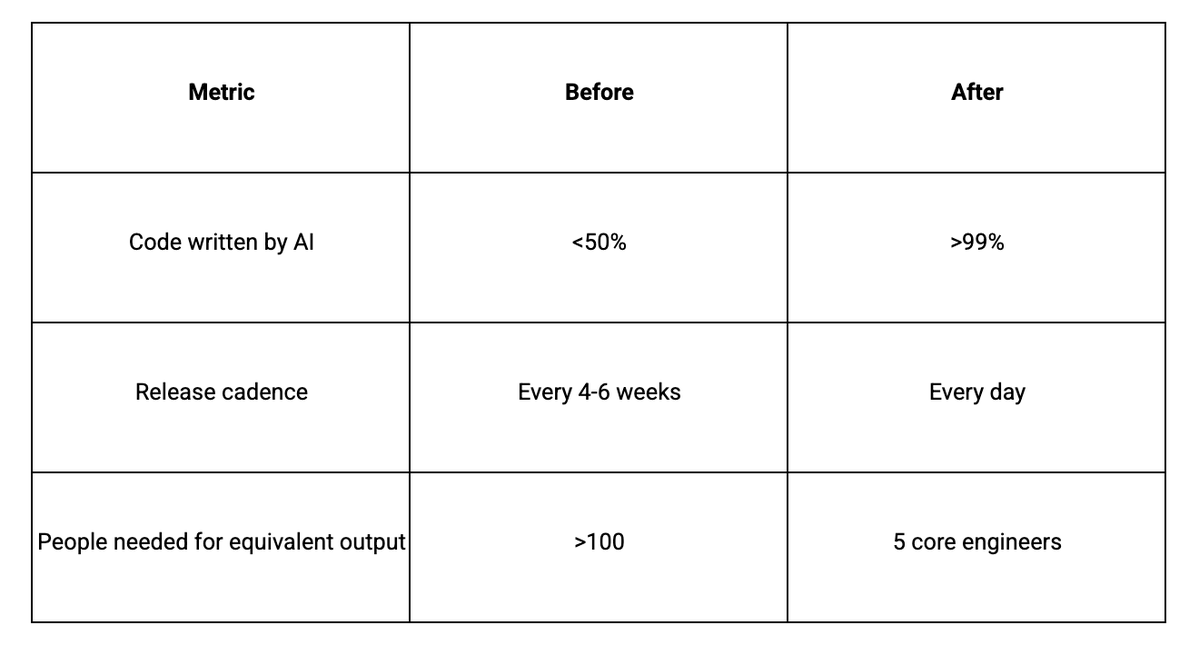
过去 14 天,我们平均每天生产部署 3 到 8 次。按旧模式,整整两周都不一定能发出一次生产版本。
坏功能上线当天就能下掉。新功能从构想到上线也在当天完成。A/B 测试实时验证效果。
很多人以为我们在拿质量换速度。实际上用户参与度上升了,付费转化也上升了。我们比以前做得更好,因为反馈回路更紧。日更团队学到的东西,永远比月更团队更多。
新的工程组织
会出现两类工程师。
Architect(架构师)
一到两个人。他们设计标准作业流程(SOP),教 AI 如何工作;搭建测试基础设施、集成系统、分诊系统;定义架构边界与系统边界;定义 agent 的“好”是什么。
这个角色要求深度批判性思维。你要批判 AI,不是跟随 AI。agent 给出方案时,架构师要找漏洞:它漏了什么失效模式?越过了什么安全边界?正在积累什么技术债?
我有物理学博士学位。这个训练最有价值的部分,不是知识点,而是质疑假设、压力测试论证、发现缺失项。未来,批判 AI 的能力会比写代码本身更值钱。
这也是最难招的角色。
Operator(操作员)
其余人都在这个角色里。工作依然重要,只是结构变了。
AI 把任务分配给人。分诊系统发现 bug、建单、给诊断并分派给合适的人。人来调查、验证、批准修复。AI 负责产出 PR,人负责判断风险。
这些任务包括 bug 调查、UI 打磨、CSS 改进、PR 审查、结果验证。都需要技能和专注,但不再要求旧模型里那种高强度架构推理。
谁适应得最快
我观察到一个意外模式:初级工程师比资深工程师适应得更快。
训练较少的初级工程师反而更有被赋能感,因为工具把他们的影响力放大了。他们没有十年的习惯包袱要先卸掉。
传统技能很强的资深工程师最痛苦。过去两个月的工作量,现在 AI 一小时就能做完。对一个投入多年才形成稀缺技能的人来说,这很难接受。
我不是在评价谁对谁错,只是在描述观察结果。在这个过渡期,适应力比累计资历更重要。
人的这一面
管理工作坍缩了
两个月前,我 60% 的时间都在管人:对齐优先级、开会、给反馈、带工程师。
现在不到 10%。
传统 CTO 模型要求你授权团队做架构、培养他们、逐步委派。但如果系统只需要一两个架构师,那我必须先自己做。我从“管理者”回到“建设者”。我大多数时候从早上 9 点写到凌晨 3 点,亲自设计 SOP 和系统架构,维护 harness。
压力更大,但我更享受“构建”,而不是“对齐”。
争论更少,关系更好
我和联合创始人、工程师的关系比以前更好了。
转型前,我和团队的大部分交流都在“对齐会议”里:讨论取舍、争优先级、争技术路线。传统模型里这些都必要,但也很耗人。
现在我仍然和团队沟通,但内容变了:聊工作以外的话题、轻松闲聊、线下活动。我们相处更好了,因为不再为那些系统可以轻松完成的工作反复争论。
不确定感是真实的
我不会假装所有人都开心。
当我不再每天都和每个人沟通时,一些同事会焦虑:CTO 不找我意味着什么?我在新世界里的价值是什么?这些担心完全合理。
也有人把更多精力花在“AI 会不会替代我”的争论上,而不是做眼前的工作。转型期本身就会制造焦虑,我也没有一个完美答案。
但我有一条原则:我们不会因为工程师引入了生产事故就裁员。我们会改进审查流程、强化测试、增加护栏。对 AI 也一样。AI 犯错时,我们要做的是加强验证、明确约束、增强可观测性。
超越工程部门
我看到很多公司做了 AI-first engineering,但其他部门仍是手工流程。
如果工程几小时能发功能,市场一周后才发布消息,那市场就是瓶颈。产品团队如果还按月规划,规划就是瓶颈。
在 CREAO,我们把 AI-native 运营推进到了所有职能:
- 产品发布说明:AI 根据 changelog 和功能描述自动生成。
- 功能介绍视频:AI 自动生成动效内容。
- 社媒日更:AI 编排并自动发布。
- 健康报告与分析摘要:AI 从 CloudWatch 和生产数据库自动生成。
工程、产品、市场、增长都运行在一条 AI-native 工作流里。只要有一个环节按 agent 速度,另一个环节按人类速度,人类速度那一段就会卡住全局。
这意味着什么
给工程师
你的价值正从“代码产量”转向“决策质量”。写代码快这件事每个月都在贬值;评估、批判、引导 AI 的能力每个月都在升值。
产品感和审美会越来越关键。你能不能在用户抱怨前就看出一个 AI 生成的 UI 不对?你能不能在架构提案里提前看到 agent 漏掉的失效模式?
我对我们 19 岁的实习生说:训练批判性思维。学会评估论证、找缺口、质疑假设。学会判断什么是好设计。这些能力会复利。
给 CTO 和创始人
如果你的 PM 流程比构建时间还慢,就先改 PM。
在规模化使用 agents 前,先把测试 harness 建起来。没有高速验证的高速 AI,只是高速积累技术债。
先从一个架构师开始。先由一个人把系统搭起来并证明可行,再让其他人逐步进入 operator 角色。
把 AI-native 推进到所有职能。
并且要预期阻力。一定会有人反对。
给行业
OpenAI、Anthropic,以及多支独立团队,都在收敛到同一套原则:结构化上下文、专业化 agents、持久化记忆、执行闭环。Harness engineering 正在成为行业标准。
驱动这一切的是模型能力这只“时钟”。我把 CREAO 的这次转变完全归因于最近两个月。Opus 4.5 做不到 Opus 4.6 能做的事。下一代模型会把这个趋势再加速。
我相信“一人公司”会变得常见。如果一个架构师加一组 agents 就能做 100 人的工作,很多公司将不再需要第二名员工。
我们还在早期
我接触到的大多数创始人和工程师仍在按传统方式工作。有人在考虑转型,但真正完成转型的人很少。
一位记者朋友告诉我,她在这个话题上只采访过大概五个人。她说我们走得比任何人都远:“我不觉得有人像你们这样把整套工作流彻底重建了。”
任何团队都能拿到我们用的工具。我们的栈里没有什么是专有的。
真正的竞争优势,是你是否愿意围绕这些工具重设计一切,并承担代价。这个代价是真实的:员工不确定感、CTO 连续 18 小时工作、资深工程师对自我价值的怀疑,以及那两周“旧系统已拆、新系统未稳”的真空期。
我们承担了这个代价。两个月后,数据会说话。
我们在做一个 agent 平台。我们用 agents 把它做出来了。