过去几周里,我有幸试驾了 GPT 5.5,而它出现的时机再合适不过。
Opus 4.7 相比 4.6 的一个倒退点是:更难“驾驭”了。工作流和技能不再像以前那样稳定遵循。
但从 GPT 5.4 跳到 5.5 完全不是这样。这个模型比之前的模型更可靠地理解你的意图,也比任何其他模型都更稳定地完成多步骤任务。
这为什么重要?
最近我刚在 @RepoPrompt 发布了一个编排工作流。 它本质上是一个技能,结合了新的高级 MCP 工具,用来管理来自不同 harness 的子代理。它允许代理并行、主动地监控多个代理,轻松处理权限弹窗和提问,并在代理偏航时及时拉回。
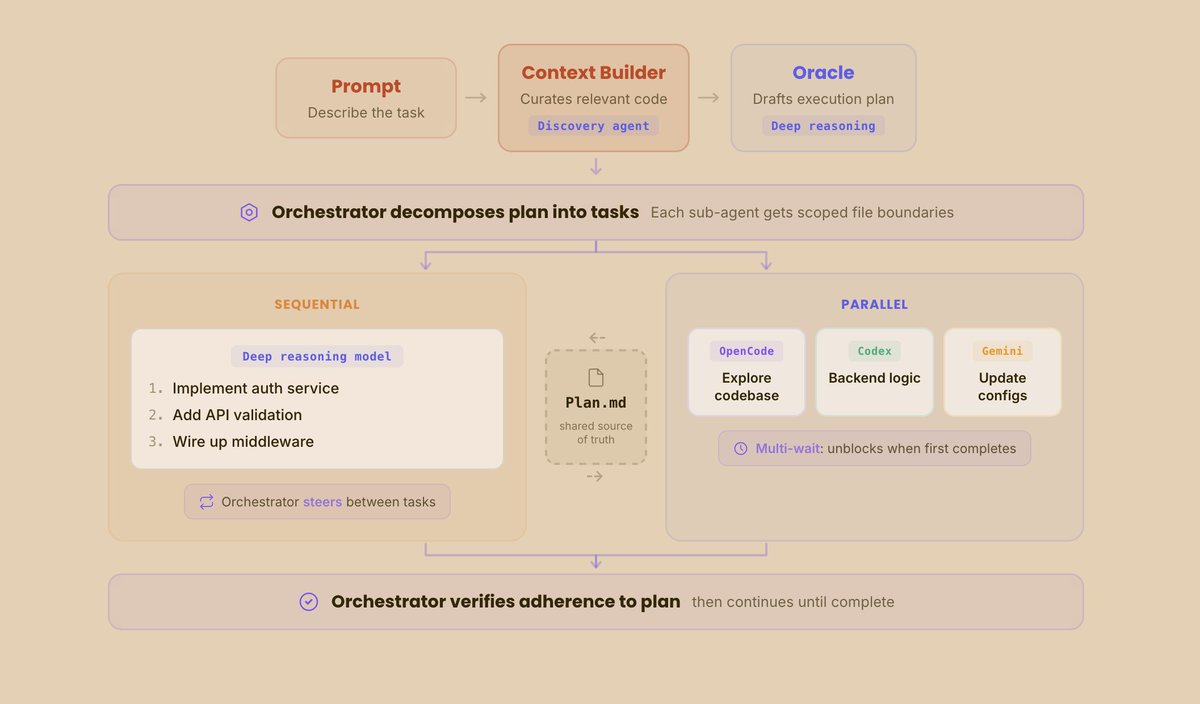
可靠的编排要求模型能够委派规划、把计划拆解成工作项,并理解哪种子代理最适合某个任务(Opus 在做 UX 工作上依然是最强,所以能识别哪些工作该交给它至关重要!)。
最重要的是——它应该成为你(用户)与那些正在操作你文件的代理之间的桥梁。模型要想发挥最好效果,需要清晰需求;而让 GPT 5.5 这样的模型夹在你和执行工作的代理之间,会让产出质量出现巨大提升。
我猜如果你只是像以前一样直接用 GPT 5.5 写代码,你大概率会觉得代码质量确实更高,但可能不会立刻感到结果层面的巨大差异。部分原因在于:上下文依然和以往一样,是最大的瓶颈。

当你把“隔离上下文”的工作拆出来,再让模型基于这份精心整理过的上下文做深度推理,结果会显著更好。在 Repo Prompt 里,我们有一个负责整理上下文的 context builder agent,还有一个负责推理的 Oracle 模型。GPT 5.5 在这两个角色里都很出色,但作为 Oracle 时,它又快又高效,而且能注意到大多数模型会漏掉的细节。

当你认真设计 GPT 5.5 这类模型的上下文窗口结构时,不用付出高昂成本也能得到专业级结果。话虽如此——ChatGPT 上的 5.5 Pro 今天也上线了,我可以告诉你,它的分析能力会让你震撼。它是个离谱强的代码审查员和架构师,但你大概不需要每天都用它。
成本 GPT 5.5 的一个缺点是 token 很贵。 虽然它的推理效率非常高,但你大概率还是希望你的工具库里留有其他模型的位置。我认为随着模型越来越贵,像我上面描述的编排方案会逐步成为常态。把请求透明地负载均衡到合适的模型上,才能在不浪费 token 的前提下,最大化利用每个模型的优势。
给正在使用 GPT 5.5 的朋友一个小提示:Codex 允许你把人格设为 friendly。这个设置不会影响质量,但会让对话体验好很多,也能去掉以往 GPT 推理模型那种机器人味。
可以看看这个,了解更多 Repo Prompt 里的编排思路。