大多数开发者都在不知不觉把自己的 AI Agent 变笨。下面拆开说说为什么。
有一个分享 AI 编码 Agent 规则的 GitHub 仓库。它有 37,800 个 star,68 位贡献者。比例是 556:1。也就是说,每 1 个写规则的人背后,有 556 个人在没读过内容的情况下直接复制。
这就是 2026 年 AI Agent 配置的现状:开发者像装 npm 包一样下载“上下文包”,把一堆自己没写过的 markdown 文件层层叠叠塞进去,然后困惑为什么 Agent 总在无视指令。
复制粘贴问题
随便打开一个经过几个月 AI 辅助开发的项目,你大概率会看到 CLAUDE.md、.cursorrules、copilot-instructions.md、AGENTS.md,可能还会再来个 gemini.md 凑齐一套。内容几乎一样,但彼此慢慢漂移。每个文件只是“技术上”被不同工具要求存在。
有开发者把这叫作“根目录里的彩纸碎屑(confetti)”。有人为了保持 5 份配置同步,干脆上了 symlink。还有人做了个 CLI 工具,写了 28 个类别、156 条校验规则,因为 AI 配置文件现在也需要自己的 linter 了。
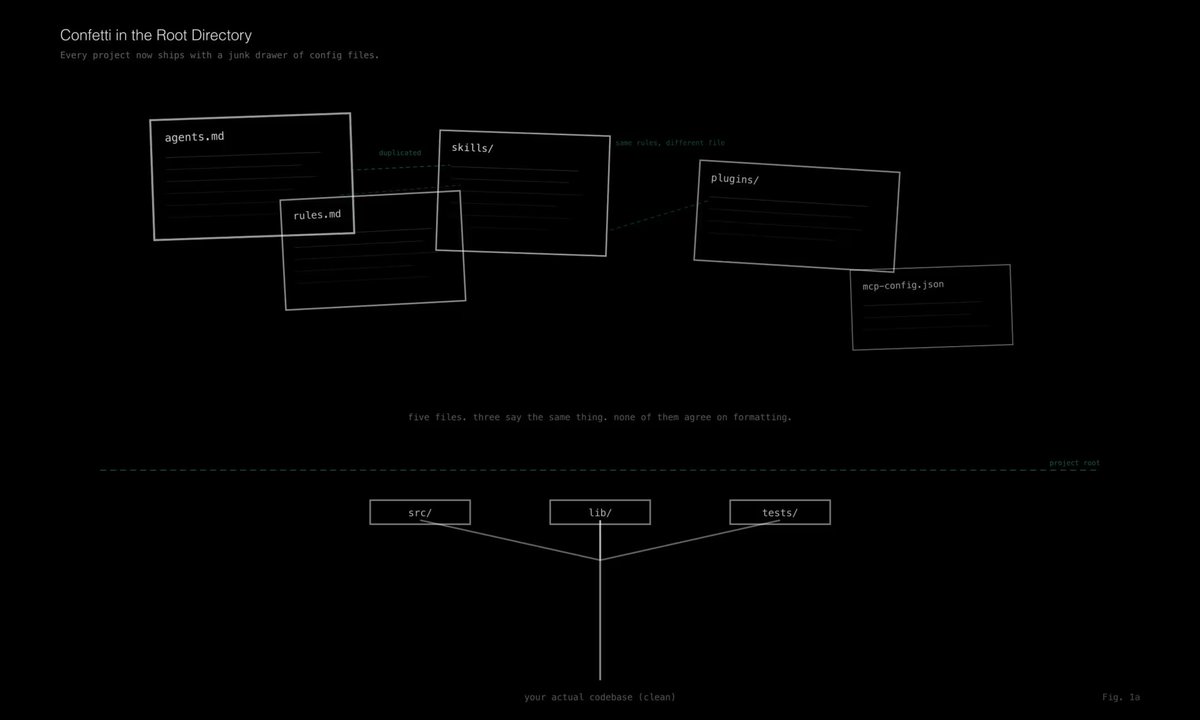
如果你见过足够多轮技术潮流,这个模式非常熟悉:有人发布“入门模板”,几千人复制,没人审计,六个月后大家都在调配置,而不是交付代码。webpack 时代我们这样干过,Docker Compose 时代也干过。
这次的区别在于:webpack 配坏了,通常只是构建变慢;Agent 配坏了,是 Agent 直接变笨。
研究已经在劝你停手
2026 年 2 月,苏黎世联邦理工(ETH Zurich)的研究者发布了一篇评估 AGENTS.md 文件的论文,横跨多个编码 Agent 和 LLM。结论很直白。
和“不给任何仓库上下文”相比,上下文文件会降低任务成功率,同时让推理成本增加 20% 以上。
加了上下文文件,表现反而比什么都不给更差,而且更贵。
论文作者后来在 Hacker News 补充说明:就算是人类亲手写的上下文文件,性能提升也大约只有 4%,而且这个提升在不同模型上并不稳定。在 Sonnet 4.5 上,性能甚至下降了 2% 以上。
CodeIF-Bench 在多轮交互式代码生成场景里测试了指令遵循能力。它的关键发现之一是:“额外的仓库上下文”会主动削弱模型遵循指令的能力。上下文越多,服从越差。研究者把上下文管理定义为关键的未解问题。
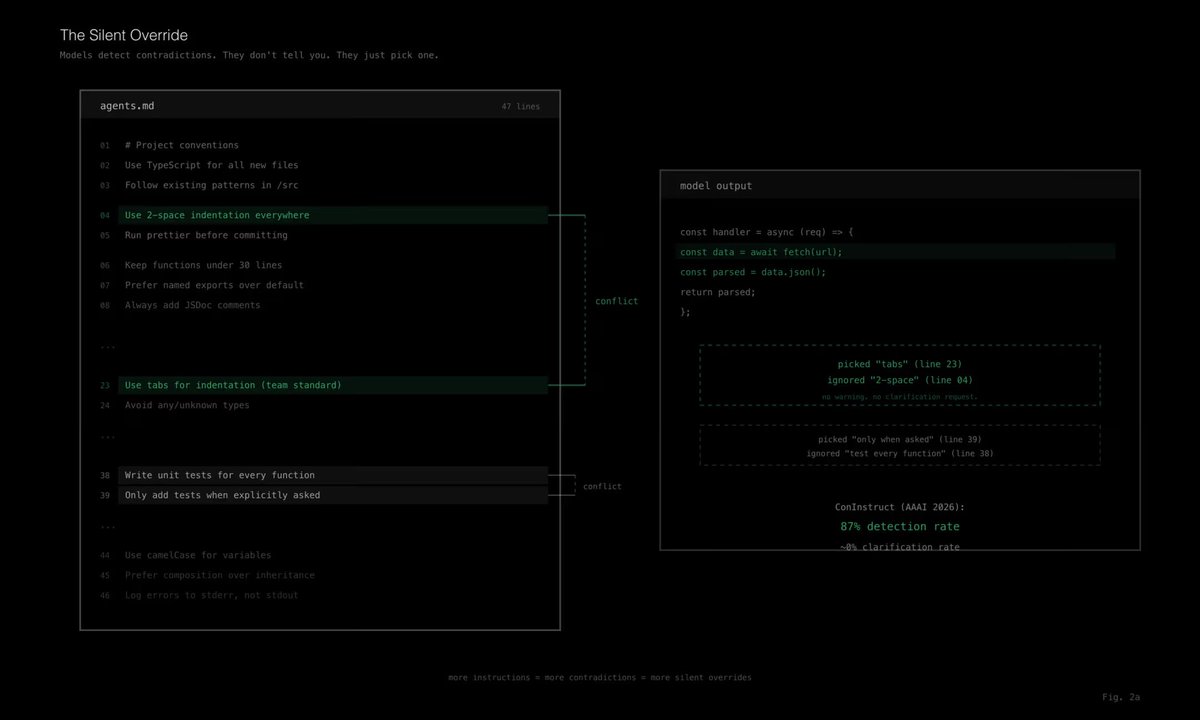
ConInstruct(AAAI 2026)更进一步:他们测试模型是否能识别指令里的冲突约束。Claude 4.5 Sonnet 在冲突检测上 F1 达到 87.3%,不算差。但问题是:即使模型发现了冲突,它几乎也不会主动提醒用户,而是悄悄选一种解释继续做。你的配置一处写“用 tab”,另一处写“用空格”。模型看到了,但不告诉你,直接自己选。
PACIFIC 证实了同一问题在“顺序指令链”上的版本:代码任务里的指令链越长,即便是最先进模型也更容易丢失上下文。这个框架会生成难度递增的基准,结果很一致:顺序指令越多,失败越多。高级模型也一样。
你的 AGENTS.md 里有多少条指令?
Anthropic 很清楚这个问题。他们自己的文档就警告过:“臃肿的 CLAUDE.md 会导致 Claude 忽略你真正的指令。”Karpathy 也说得很直接:“信息太多或不相关,LLM 成本会上升,性能可能下降。”
Birgitta Böckeler 在 Martin Fowler 网站上的原话是:“当 Agent 接收太多上下文时,它的效果会下降;而且过多上下文本身也是成本因素。”
规则越多,输出越差。
那我们为什么还在继续
因为我们不信任 Agent。
根据 Stack Overflow 2025 调查:84% 的开发者正在使用或计划使用 AI 工具,但只有 29% 信任它。这个数字还比之前的 40% 下降了。
当你不信任某样东西时,你会过度规格化。你会写一个 200 行的 AGENTS.md 去解释目录结构,因为你不相信 Agent 自己能看懂。你会加上那些其实 linter 已经强制的代码风格规则。你会把架构文档粘进去,哪怕 Agent 本来就能从仓库里读到。
两年前,这么做是有道理的。早期 Agent 确实“盲”,看不到你的代码库,你只能解释一切。
但这种肌肉记忆留了下来。Agent 变强了,上下文引擎也变强了。工具现在能读你的代码、依赖、git 历史、文件结构,并自动归纳模式。开发者却还在给“旧版本的盲 Agent”写说明书。
Tim Sylvester 对这种挫败循环总结得很到位:“你写下长长一串规则,Agent 尽职地无视它们。你指出问题,它会说‘你说得对’,然后道歉。但这些道歉只是机械流程。很多人都在现实关系里经历过这个。”
最后那句戳中人,是因为它是真的:当某个对象不听你时,直觉是更大声重复。更多规则,更多细节,更多强调。对人没用,对 Agent 也没用。
研究说这条路刚好走反了。
两个桶
修复方法是先分清:哪些上下文该放在哪里。
第一桶:Agent 本来就看得见的东西。你的代码、目录结构、依赖、git 历史。好的上下文引擎会读这些,你没必要再写进 markdown。那相当于给已经 clone 仓库的同事再写一份“仓库导览”。
第二桶:Agent 看不见的东西。怎么部署、怎么跑测试、团队里只存在于人脑中的约定、你的 staging 环境长什么样、以及三个月前那个奇怪架构决策背后的原因。
多数人用第二桶的工具去解决第一桶的问题:在 AGENTS.md 里描述代码结构,补充代码里明明可见的 API 模式。Agent 其实知道。你只是在制造噪音。
好的上下文引擎会读代码库,所以你不需要重复解释。你越少告诉 Agent 那些它已经看得见的内容,它就越有注意力预算留给真正推不出来的信息。
📷
真正有效的做法
Vercel 做过一轮评测,用 Next.js 16 API 比较两种方案:skills(按需检索)和 AGENTS.md(被动上下文)。skills 相对基线是 0 提升。Agent 明明能访问文档,但它根本没去看。
然后他们试了一个更“笨”的办法:把整个文档索引压缩进一个 8KB 的 AGENTS.md。不是完整文档,只是可检索文件的索引。结果在 build、lint、test 上拿到 100% 通过率。
40KB 压到 8KB,满分。最后“笨方法”赢了。
Jan-Niklas Wortmann 也走过类似路径:从 80+ 行“理想规则”开始,砍到 30 行“由真实失败反推”的指令,结果是“行为显著更好”。他最后用的删减准则是:“有失败证据吗?能被工具强制吗?编码了决策吗?可被触发吗?四项全不满足就删。”
从空白开始。只添加能阻止失败的内容。再验证它确实有帮助。
该删什么
现在就打开你的 AGENTS.md 或 CLAUDE.md。对每一行问一句:如果没有这行,Agent 会犯错吗?
如果不会,删掉。
几乎肯定不该放进去的内容:
你的目录结构(Agent 看得见)。你的技术栈(在 package.json、Cargo.toml 或 go.mod 里)。那些 linter 已经强制的编码风格规则。(“永远别让 LLM 干 linter 的活。”)你现有代码里已经清晰可见的 API 模式。“写干净代码”“遵循 SOLID”这类泛泛最佳实践。Agent 在互联网语料上训练过,它知道这些。
真正该保留的:build/test/lint 命令,部署步骤,环境初始化,存在于团队脑内的协作约定,已知坑点,以及那些从代码表面看不出来的架构决策。
DHH 说得很直接:“约定优于配置(Convention over configuration)这套理念,给过去 20+ 年 AI 训练提供了大量优质数据。”如果你的代码库遵循惯例,Agent 已经理解了它。你没必要给一个看过全网 Rails 应用的模型再讲一遍 Rails。
最好的 Agent 配置,不是文件最多的那个,而是每一行都能阻止一个具体失败的那个。
注意力预算
你的 Agent 系统提示里本来就有几十条指令。过去一年几乎所有基准都在重复同一件事:约束密度越高,指令遵循越差。CodeIF-Bench 在交互式编码里看到这一点,PACIFIC 在顺序代码任务里看到这一点,ConInstruct 则看到模型遇到冲突时宁可沉默忽略也不主动提问。这意味着,留给 AGENTS.md、skills、插件和你真实提示词的窗口本来就很窄,而且它们是合并竞争的。
你每加一行,就会把别的东西挤出去。一条关于目录结构的规则,可能会挤掉一条部署关键步骤。一个泛化最佳实践,可能会挤掉项目专属坑点。你其实是在决定“哪些内容会被忽略”。
把每一行都当广告位。它必须配得上租金。
再一次:约定优于配置
Rails 社区 20 年前就解过这个问题的一个版本。Rails 之前,什么都要配:数据库映射、URL 路由、文件位置,全显式、全手工。Rails 说:遵循约定,少写配置,框架自己推断。
Agent 正在走向同一个方向。现在工具已经能从代码库自动提取上下文。多数开发者的习惯还没跟上。
测试题
现在就打开你的 AGENTS.md。对每一行问一句:它是否在阻止 Agent 真实会犯的错误?
如果你指不出具体失败案例,就删掉这一行。
当留下的每一条真的被执行时,你会明显感觉到差别。