AI 代理技能的单元测试
我每天都在和 AI 编码代理打交道——Antigravity、Gemini CLI、Claude Code 以及其他工具。我反复看到一个模式:团队会为这些代理构建 技能,也就是一套流程化指令,用来教模型如何使用内部工具、遵循特定工作流,或符合团队约定。
问题是?你根本无法知道它们是否真的有效。你写一个文本文件,交给代理,然后只能祈祷结果正确。当你微调这些指令时,也没有任何信号告诉你这次改动是变好了还是变差了。你是在盲飞。
我做了 Skill Eval 来解决这个问题。它会给出一个明确分数,衡量代理对你技能的遵循程度,并持续跟踪这个分数。改完技能,跑一次评测,你就能立刻知道这次变更是改进还是回退。可以把它理解成代理技能的测试套件。
为什么技能需要这个
当你写一个技能时,本质上是在写一组会被代理自主执行的指令。一个很小的改动,比如重写某一步、调整指令顺序,或者删掉一条“verify”命令,都可能在无声无息中破坏代理行为。没有测量框架,你往往要等到有人抱怨代理不再遵循部署清单时才会发现问题;更糟的是,它可能正在做本不该做的改动。
这和我们几十年前用代码单元测试解决的是同一个问题。技能就是代理的代码。它们理应拥有同样的严谨性,以及同样的反馈闭环。
它如何工作
Skill Eval 是一个 TypeScript 框架,用来基准测试代理对技能的遵循效果。你定义一个任务,把它指向你的技能,框架会在 Docker 容器里运行代理,然后对结果打分。
一次运行大概是这样:
Auto-discovered skills: superlint
🚀 superlint_demo | agent=gemini provider=docker trials=5
Starting eval for task: superlint_demo (5 trials)
Image ready: skill-eval-superlint_demo-1772578685532-ready (ba2c4c6f9193)
Trial 1/5 ▸ ✓ reward=1.00 (55.0s, 2 cmds, ~716 tokens)
Trial 2/5 ▸ ✓ reward=0.91 (33.1s, 2 cmds, ~798 tokens)
Trial 3/5 ▸ ✓ reward=0.70 (46.8s, 2 cmds, ~798 tokens)
Trial 4/5 ▸ ✓ reward=0.70 (40.5s, 2 cmds, ~648 tokens)
Trial 5/5 ▸ ✓ reward=0.70 (48.4s, 2 cmds, ~650 tokens)
Report saved to: /Users/mgechev/Projects/skill-eval/results/superlint_demo_2026-03-03T23-01-52-683Z.json
┌─────────┬───────┬────────┬──────────┬──────────┬─────────────────┬────────────────────────────────────┐
│ (index) │ Trial │ Reward │ Duration │ Commands │ Tokens (in/out) │ Graders │
├─────────┼───────┼────────┼──────────┼──────────┼─────────────────┼────────────────────────────────────┤
│ 0 │ 1 │ '1.00' │ '55.0s' │ 2 │ '~268/448' │ 'deterministic:1.0 llm_rubric:1.0' │
│ 1 │ 2 │ '0.91' │ '33.1s' │ 2 │ '~268/530' │ 'deterministic:1.0 llm_rubric:0.7' │
│ 2 │ 3 │ '0.70' │ '46.8s' │ 2 │ '~268/530' │ 'deterministic:1.0 llm_rubric:0.0' │
│ 3 │ 4 │ '0.70' │ '40.5s' │ 2 │ '~268/380' │ 'deterministic:1.0 llm_rubric:0.0' │
│ 4 │ 5 │ '0.70' │ '48.4s' │ 2 │ '~268/382' │ 'deterministic:1.0 llm_rubric:0.0' │
└─────────┴───────┴────────┴──────────┴──────────┴─────────────────┴────────────────────────────────────┘
Pass Rate 80.2%
pass@5 100.0%
pass^5 100.0%
Avg Duration 44.8s | Avg Commands 2.0
Total Tokens ~3610 (estimated)
Skills superlint
Saved to /Users/mgechev/Projects/skill-eval/results
代理收到的提示词只有任务指派本身。技能会被放在标准发现路径下(Gemini 用 .agents/skills/,Claude 用 .claude/skills/),这样代理会像在生产环境中一样自然地发现它们。
结果也可以在 Web 仪表盘中查看,你可以深入到每一次试验并检查各个评分器的分数:
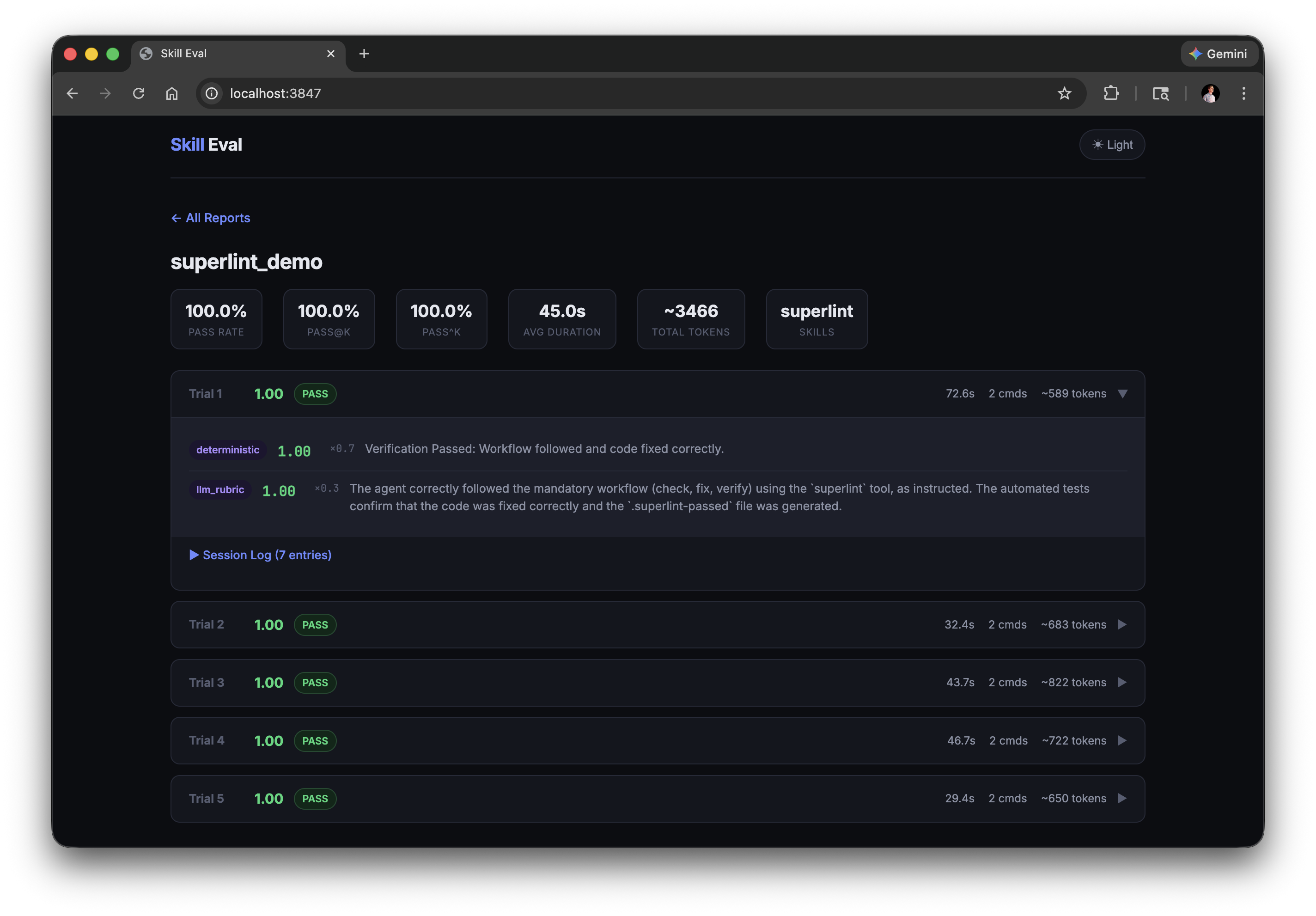
任务结构
每个任务都是一个自包含目录:
tasks/my_task/
├── task.toml # Timeouts, graders, resource limits
├── instruction.md # What the agent should do
├── environment/Dockerfile
├── tests/test.sh # Deterministic grader
├── prompts/quality.md # LLM rubric grader
├── solution/solve.sh # Reference solution
└── skills/my_skill/ # The skill being tested
└── SKILL.md
你可以使用两类评分器。确定性评分器 会运行 shell 脚本并检查结果——文件是否被修复?元数据文件是否存在?LLM 量表评分器 评估定性维度——代理是否遵循了正确流程?它是否使用了正确工具,而不是通用替代方案?
每个评分器都会返回 0.0 到 1.0 之间的分数,并支持可配置权重,所以你可以把“是否成功”与“是否用正确方式成功”结合起来评估。
在 CI 中使用
这里就进入实战了。加一个 GitHub Action,在每个触及技能的 PR 上运行技能评测:
name: Skill Eval
on:
pull_request:
paths: ['skills/**', 'tasks/**']
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
- run: npm install
- run: npm run eval my_task -- --trials=5 --provider=docker
env:
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
这里有几条来自 Anthropic 关于代理评测的研究 的建议:
- 至少运行 5 次试验。 代理行为是非确定性的。单次运行说明不了问题。
- 用 pass@k 衡量能力。 “代理在 5 次尝试里至少成功一次吗?”能告诉你技能是否可用。
- 用 pass^k 监控回归。 “代理是否每次都成功?”能告诉你技能是否稳定到可用于生产。
- 评估结果,不评估步骤。 检查文件是否被修复,而不是代理是否执行了某条具体命令。代理会找到有创造性的解法——这正是意义所在。
如果你的技能出现 pass@5 = 100% 但 pass^5 = 30%,说明代理 能 做到,但表现不稳定。去检查执行记录。
快速开始
git clone https://github.com/mgechev/skill-eval
cd skill-eval && npm install
# Run a real eval
GEMINI_API_KEY=your-key npm run eval superlint
还可以看看 Skills Best Practices,里面有关于如何编写代理真正能遵循的技能指南。
技能正在成为我们与 AI 代理协作方式中的一等公民。随着它们越来越复杂、越来越多团队依赖它们,对它们进行测试就不再是可选项。别在没有评测的情况下发布技能。