引言
在这份技术报告中,我们介绍一种新的智能体架构模式,并展示单线程智能体如何超越 ReAct 与 RLM 的范式进行泛化。
Random Labs 的目标是构建通用的、非为跑分而优化的端到端软件工程智能体。本报告的内容让我们朝这个目标更进一步。
我们先审视现代基于 LLM 的智能体所面临的一系列问题:长时程任务、战略与战术的平衡、以及工作上下文管理。我们会探讨现有解决方案及其局限。在列举完现代智能体面临的问题之后,我们将描述 Slate 的架构:一种基于线程的情节记忆系统,它能同时解决上述所有问题。
背景
要构建能泛化的智能体,需要解决三个相互叠加的问题:长时程任务执行、战略与战术推理之间的平衡、以及工作记忆管理。这些问题单独看都可以解决——难点在于它们会相互影响。
理解长时程任务
长时程任务具有路径依赖性(任务所需的行动彼此依赖),而成功所需的最小步骤数又超过了一个最小化的 harness 所能覆盖的范围。这里所说的最小 harness,是指仅围绕模型做一个有限的工具调用循环、且没有额外规划或记忆基础设施。Terminus 和 Simple Codex 都属于这一类,而你真正用来完成工作的多数智能体并不属于这一类。[4][5]
要解决这类任务,智能体需要三样东西:足够的工作记忆,使模型能在正确的时间关注到正确的上下文;战略与战术执行之间的平衡,使模型既能规划好也能正确执行;以及能在任务过程中整合新信息而不丢失总体目标的能力。
工作记忆
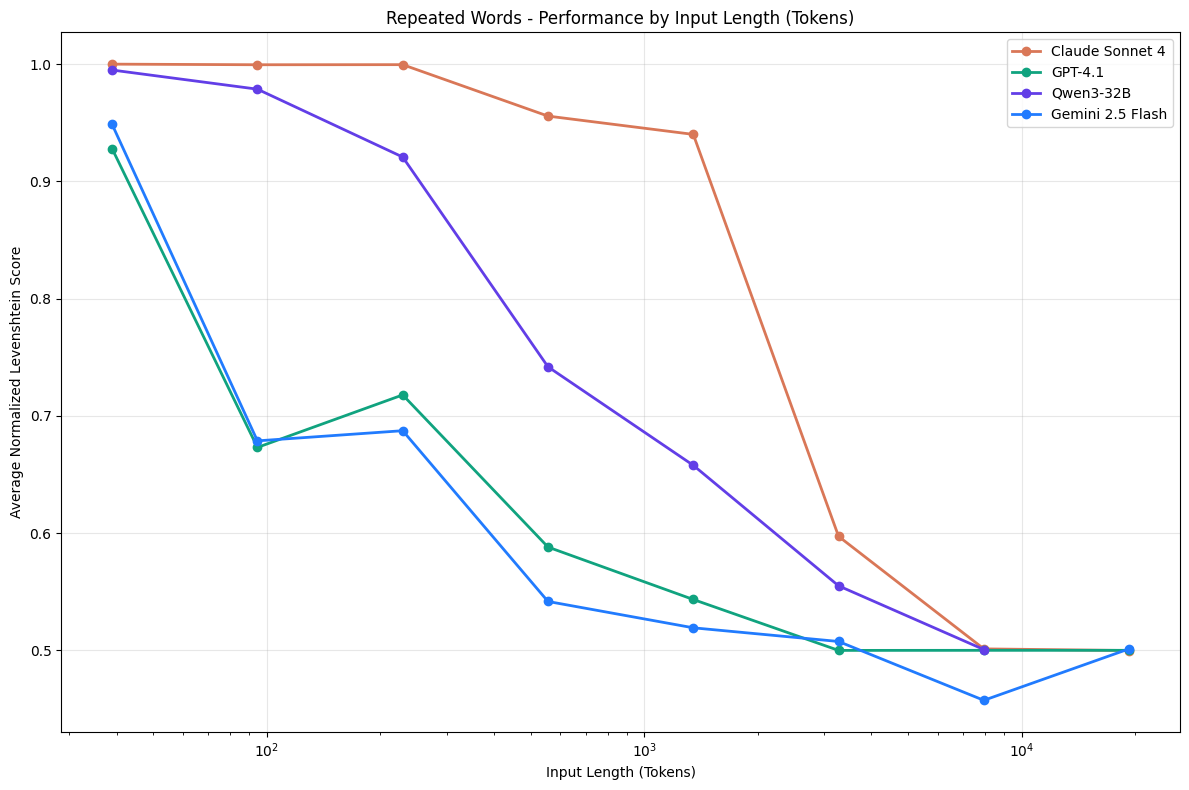
模型无法在其上下文窗口上均匀地注意。随着上下文长度增长,模型的注意力会衰减。可用的部分,即尚未进入衰减区域之前的那段,就是工作记忆。Dex Horthy 把上下文窗口中检索质量下降的部分称为“Dumb Zone”。[6] 工作记忆实质上就是在那之前的上下文窗口范围。[25]
Context Window & Dumb Zone
Performance Degradation vs. Input Length [24]
战略与战术
战略是基于知识的开放式规划,用来引导系统朝目标前进;战术则是学习到的、局部的行动序列,能实质性地推动目标达成。有趣的是,这一区分正好对应于强化学习历史上如何解决围棋、国际象棋等游戏。在国际象棋中,像 Stockfish 这样的传统引擎会对走子树进行暴力搜索(某种战术型搜索算法)[16]。相对地,自我博弈式 RL 产生的系统会学习哪些局面在战略上更重要。
“在一些对局中,AlphaZero 为了长期的战略优势而牺牲子力,这表明它的局面评估更为流动、依赖上下文,相比之前的棋类程序所使用的基于规则的评估更胜一筹。”[11]
Brute Force vs. Value / Policy Execution
围棋把这种区分表现得更明确:战略关注势、地盘均衡与全局思考;战术关注读(计算具体局部序列)与死活问题。当 DeepMind 构建 AlphaGo 时,这种划分被直接体现在架构中:价值网络负责局面判断(战略),而策略网络负责落子选择(战术)。[14] 对 AlphaZero 训练时内部表征的研究发现,战术概念——如子力价值——最先被学到,其后才是王的安全、机动性等战略概念。它们在不同训练阶段、不同网络层分别出现。[12]
AlphaZero: Concept Emergence by Training Stage
“……子力价值是一个关键概念,最先被建立。随后出现的是机动性相关的问题(王的安全、攻防)。最后进入精炼阶段,网络学会进行复杂的权衡……”[12]
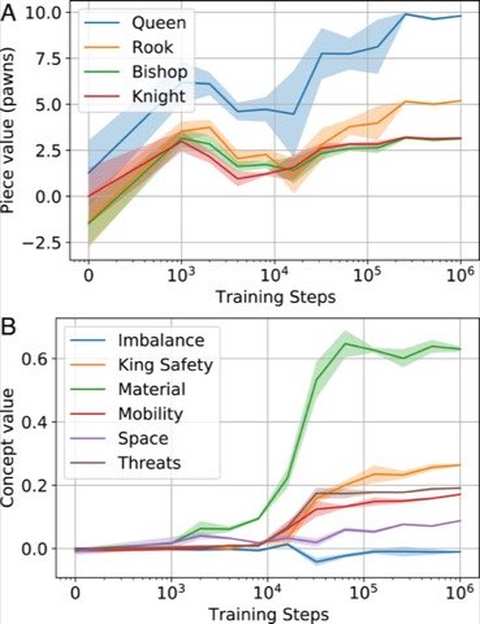
论文中由前世界冠军 Владимир Kramnik 的定性评估直接证实了这个顺序:在 16k 步时 AlphaZero 输在子力;到 32k 时已对子力价值有稳固掌握;32k 到 64k 的跃迁主要由不平衡局面中的王的安全驱动。超过 128k 之后的收益来自于知道哪些攻击会成功——接受子力牺牲并将其转换为优势——而不是来自于位置或残局的提升。先战术知识,后战略判断。
软件工程作为一个开放式的长时程游戏
我们把软件工程视为一个更开放、几乎无限的游戏,战略与战术都相关,取决于所处理的任务。例如,记住并执行一个 bash 命令是简单的战术;设计一个在演化中保持向后兼容的 schema 则更偏战略。
Strategy vs. Tactics Spectrum
这可以从这样一个事实看出:如果让模型写一个计划或逐步思考任务,它实际上先被赋予了一个知识检索任务,然后才是一个代理式执行任务。最初的计划/思考可以看作模型检索知识并为解决路径做战略化思考,然后再使用战术去执行计划。
顺带一提——AGENTS.md 文件里的多数规则其实都是战术性的,比如“绝不要运行 db 命令”。
既有方法
没有任何既有方法能同时解决上述所有问题。每种方法都会在解决其中一两项的同时牺牲其他方面。
解决工作记忆并战胜 Dumb Zone
最先想到的解决方案是压缩模型的上下文!只要我们能可靠地周期性丢弃无关上下文,就能解决问题。这一策略称为 compaction(压缩归并)。
Compaction
Compaction 是单独解决工作记忆问题的一种朴素方案。
Compaction 仍基本未被解决。大多数“compaction”实际上是有损压缩(尽管已经有所改进)。
早在 2025 年初(大约 5 月),我们构建了(最早的一批)基于滑动窗口的智能体之一,它能运行极长的会话长度(用户报告最高可达 2 天)。该智能体已弃用,但仍以 npm 包形式提供:
npm i -g @randomlabs/slatecli
现实中有一些可用但有损的压缩案例:
- Claude Code 中的 compaction(臭名昭著地糟糕)
- Geoffrey Huntley 的著名 Ralph Wiggum 循环[17]
- Amp 的 handoffs(深受欢迎,但需要用户指导)[18]
在这里 Amp 可能有最有趣的实现,因为 handoff 被设计为引导一个全新智能体会话的启动。
Compaction 的主要问题在于它并不是确定性有损,这意味着我们可能会不可预测地丢失重要信息。
子智能体
为避免 compaction 的损失性,我们可以尝试隔离不重要的上下文。这就是子智能体的用武之地。
子智能体是单独解决工作记忆问题的第二种朴素方案。子智能体相对有效,它们会隔离上下文。但这种隔离导致朴素实现无法跨上下文边界传递信息,因为它们只返回一条响应消息(参见 codex/claude-code 子智能体)。
Markdown 规划
为了在任务不同部分、compaction 以及隔离的子智能体上下文之间保持一致性,我们可以在一开始就制定计划。
Markdown 计划也是平衡战略与战术的一种方式。通过要求模型先规划任务,它迫使模型运用其 知识 来进行战略化思考,这通常会比直接依赖其学到的行为得到更好的结果。再给模型一种在文档中跟踪任务进度的战术,使模型能反复刷新对自身 战略 的理解,并在任务过程中保持对齐。
随着模型改进并在这种基于 Markdown 计划的战略化方式上受训,模型能通过一个简单 Markdown 文件完成的任务将必然扩大范围。然而,规划与直接利用学得行为之间可能始终存在差别。
我们可以把这称作知识悬置(knowledge overhang):模型理论上可访问的知识,但若没有诸如“逐步思考”或在文件中规划之类的技巧,它在战术上无法触达。[22]
Knowledge Overhang as Rollout Sampling
这类规划能走多远必然有上限。这个上限会随着模型变强而提高。
三个关键失效模式:
- 模型在写计划时不够全面(计划细节不足)
- 模型在执行计划时不够全面(模型跑偏、遗漏计划中的部分)
- 模型忘了它有自由意志,它学到的战术不允许它适应新信息(忘了朝正确方向更新计划)
我们大概都见过过于简略的计划,然后再要求模型补充细节。也见过模型不完整地执行计划,或在计划尚未完成前提前宣布胜利。此外,模型还必须记得在遇到新信息时更新计划,而这从来不是保障。
这三类失效模式随着针对此类规划的 RL 改进而有所改善(你只需看看过去一年你如何使用这些工具),不过这些失效模式需要直接的 RL 来对抗它们。随着 RL 后训练投入的增加,对于固定任务复杂度,这些失效的发生率会下降,但对模型而言它们仍然是非直觉的(从逻辑上讲,正是因为需要训练这种行为)。
直接任务分解
Markdown 计划会变陈旧,因此下一步是让执行结构变为强制,并在推进中更新它。通常会实现为任务树,模型必须先完成每个节点才能继续。这解决了过早停止的问题,并可借助子智能体上下文隔离来提高彻底性。(参见 ADaPT[19])
在这种系统中,模型接收一个主任务,生成子任务,希望完成子任务,然后回到主任务继续完成。
Direct Task Decomposition Tree
为了更彻底,你还可以为任务引入一个门控机制,要求模型按照 N 个不同步骤走完,才能把任务标记为完成。
两个主要失效模式:
- 系统由于线性任务依赖而难以适应新信息
- 系统没能完全分解主任务,导致子任务及其结果未被整合
是否如此就留给读者自行验证(试试 gpt2-codegolf 任务[20])。但严格地让智能体沿任务树执行,每个任务都带验证步骤并被一系列操作门控,确实能让智能体不跑偏,但也不给智能体灵活执行任务的空间。
使用这种门控任务树的核心前提是避免模型容易出现的过早停止失效,但你最终会用流程的刚性换掉自然语言与隐式规划的灵活性。
直觉上,对结构化任务数据的依赖是主要罪魁祸首,同时也是彻底性的驱动因素。
这种刚性让系统整体更难表达多样行为,也难以灵活处理任务。我们可以说系统的 可表达性 很低。
可表达性与归纳偏置
当一个智能体 harness 能用相对少的输出操作实现许多可能的终态时,它就具有较高的可表达性。
为了说明不同工具的可表达性,考虑两个 harness。Harness A 只有 file_read 工具,Harness B 只能使用 sed 命令。无论 Harness A 多努力,也不管模型多强,Harness A 都无法表达“编辑文件”的操作。另一方面,尽管在 token 上可能不够高效,Harness B 却完全能够读取、写入、搜索文本等。这源于 sed 工具的可表达性:你可以通过略复杂的接口表达更广泛的操作。
Harness Expressivity: Reachable Behavior Space
系统的可表达性很重要,但同样重要的是模型能否使用它。模型使用提供的 harness 的能力,直接取决于该 harness 接口在模型训练分布中的“贴合度”。
比如,考虑两个高度可表达的系统:Bash 与 Python REPL。
模型对它们用途的训练数据存在差异。带有 Python REPL 的 harness 可以 完成与 Bash shell 环境类似的大量工作,但模型完成任务的速度取决于相关操作在训练数据中的普遍程度。例如,一个任务要求智能体在 Ubuntu VM 中解决带 C 绑定的包问题并使用修补后的包,这在 Python REPL harness 中可能比在 Bash harness 中更具挑战。
模型对这些不同 harness 的使用方式存在偏置,尽管它们在 理论上 同样可表达。
模型的归纳偏置、系统的可表达性以及采样方法共同导致了我们观察到的具体行为。作为 harness 构建者,目标是让期望的行为成为自然行为。
注:这里的归纳偏置指模型从原始预训练到基于 rubric 的后训练所偏好的默认行为。
作为 harness 构建者,你的工作是设计一个系统,让系统自然表达所需行为。系统表达这些行为的能力取决于 harness 的可表达性以及模型的归纳偏置形态。
回到任务分解问题:严格的任务图强迫模型按步骤执行,会显著限制系统的可表达性。
RLM 与递归分解
智能体系统需要一种更灵活的方式来分解并执行任务。RLM 是最接近平衡这些需求的方法。它不强制固定分解,而是给模型一个 Python REPL 以及递归运行操作的能力,让任务结构自然从模型自身的推理中浮现,而不是预先施加。
子调用(无论是直接 LLM 查询还是类似 RLM 的子智能体)封装了上下文;REPL 允许模型迭代地适应问题,而不是被迫一次性“发射并遗忘”;模型在 Python 脚本 上有大量训练数据,因此熟悉接口并倾向于使用它;上下文可以通过引用传递以保持事实源;而模型具备 自然 分解任务的能力,且不被强制。
本质上,任务分解只要拥有合适的原语与模型偏好的接口,就会自然涌现。
但有一个问题。
注意官方实现有一个有限深度?[2] 它只讨论了 depth=1。当真正允许递归(depth=N)时,模型需要一个防止过度分解的护栏。不是说模型一定会过度分解,但它可能会,尤其是在被要求分解时。一旦接口提供了无界分解,harness 就需要底层的护栏来抑制过度分解。
不过还有第二个问题:系统如何在执行过程中适应新发现的数据?REPL 缺少中间结果,这意味着模型必须在该步一开始就提交完整计划,只在末尾才知道是否成功。想象你在解一个迷宫,却必须盲猜 n 步后的位置。在这个世界里,你唯一的反馈是最终落点。若环境在变化,你几乎没有修正空间。你要么走出迷宫,要么走不出来。
Blind N-Step Execution
这可以被描述为栈层之间缺乏同步。模型把操作交给某个系统(LLM 或程序)_隔离地_处理并只返回最终数据,这限制了主模型在执行计划时对失败的适应能力(即 REPL 中的程序)。对于读取静态环境中的信息,这没问题;但在实现任务时,这种缺乏同步的刚性就很成问题。
顺带一提……结合上述观察与对深度研究型智能体的理解,会暴露出一种非常具体的上下文工程模式:基于栈的隔离非常适合研究,因为它能把检索任务分解为对不可变数据的隔离操作,然后再综合结果。
过度分解与刚性是 ReAct 类智能体不会遭遇的失效模式,因为规划与执行是隐式的、逐回合进行,模型可以灵活反应。[21]
现在,任何试图构建智能体的人都会想到:“那我做一个规划器智能体,然后一个实现者智能体,再加一个审阅智能体?”
让我省你这一折腾。它会“差不多能用”,但你会在使用时讨厌它到骨子里。它慢、笨重、工作时惯性极大。这主要是因为执行模式太严格,没有让模型智能地决定如何处理任务。这可能提升 benchmark 分数,但不会真正改善你的开发体验。执行过程中保持整体可表达性 极其 重要。
有一些智能体架构遵循了这个原则:Devin、Manus、Claude Code,以及 Altera 的 Sid 项目(现为 shortcut)。
Devin、Manus 与 Altera
Devin、Manus 与 Altera 的 PIANO 架构都落在“高层计划、低层执行”的范畴,并通过某种方式同步系统 1 与系统 2 的思考,从而得到一个具有持久状态的长时程智能体。[7][8][9][10]
它们遵循的模式是:由高层规划智能体进行策略制定,把任务委派给低层子智能体,将低层智能体的上下文压缩为某种摘要,然后把该格式化上下文返回给高层智能体以实现同步。Altera 的方法还允许智能体同时进行多种处理。
这种规划方式容易出现与前述“任务分解”或 “RLM” 部分相同的失效:过于严格的执行约束会降低系统对新信息的反应能力,并必然让子智能体像脚本一样以同样方式失败。
同步子智能体(主智能体阻塞等待子智能体结果)更可靠,但很慢。异步子智能体则引入另一个问题:何时以及如何对结果进行对账。
Devin / Manus / Altera: Strategize–Delegate–Compress Cycle
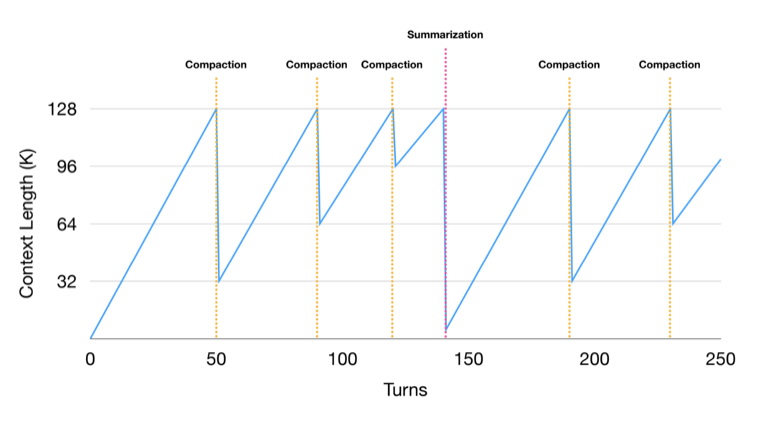
Codex 与 Claude Code
这些方式极其简单。它们把工作委派给子智能体(类似一段 prompt),子智能体完成后返回。
这种做法明确引入了同步问题,因为主线程与子线程上下文隔离,只能依赖某种消息传递(这里是发送 prompt、接收响应)。这就是为什么子智能体最初更适合用来做搜索——多数搜索是探索性的,而且其实不需要保留太多上下文。
幸运的是,实验室可以训练模型擅长委派子智能体、也擅长作为子智能体。这不是应该下注反对的事情。
Claude 不必要地为子智能体定义了持久角色,但这源于其同步方式是消息传递(我们认为在主线程 + 子线程架构、基于当前模型行为,这种方式并不正确;不过模型会更擅长这一点,因为它们会被训练)。
我们认为单线程智能体尚未被完全解决。作为行业,我们还不需要转向团队式多智能体。
Agent Architecture Taxonomy
| aspect | ReAct | Markdown Plan | Task Trees | RLM | Devin / Manus / Altera | Claude Code / Codex | Slate |
|---|---|---|---|---|---|---|---|
| planning | implicit | file | explicit | REPL | planning agent | plan mode | implicit |
| decomposition | none | none | direct tree | REPL functions | task based | subagent delegation | implicit |
| synchronization | single thread | single thread | gated steps | REPL return | reduce & return | message passing | episodes |
| intermediate feedback | per step | per step | on task failure | on execution | after compress | message passing | per episode |
| context isolation | N/A | N/A | per subtask | per subcall | subagent | subagent | per thread |
| context compaction | N/A | N/A | Task based | REPL Slicing | Subagent compress | Compaction | Episode compress |
| parallel execution | N/A | N/A | N/A | In REPL | Altera only | Native | Native |
| expressivity | high | high | low | high | medium | medium | high |
| adaptability | Yes | Yes if plan updated | No | Yes | Yes | Limited by message passing | Yes |
Slate 的方法:线程编织与情节
总结一下我们已经覆盖的内容:
- Compaction:如何在保留关键信息的同时压缩智能体轨迹
- 战略一致性:如何让智能体对问题进行战略思考,并在问题推进过程中保持与该战略对齐
- 可表达性:设计接口,让智能体表达更复杂的行为
- 任务分解:如何拆解任务并解决子问题,同时在最高层保持灵活性
- 同步:如何在执行上下文隔离的前提下同步系统内各处的工作
在本节中,我们提出一种架构原语来解决这些问题:线程。关键洞见是:在编排线程与工作线程之间进行频繁且有界的同步,可以在速度、延迟与智能之间取得真正可用的平衡。
线程
想法很简单:用高度可表达的接口来访问模型的知识悬置,让它在不关注实现战术细节的情况下对行动进行战略规划。一个中央编排智能体通过高度可表达的接口把行动委派给工作线程(可以是工具、CLI 等;我们选择 DSL 是因为拥有编程模型的灵活性)。工作线程执行行动,然后返回给主编排线程。
听起来像子智能体?不完全是。
线程非常具体。每个线程执行一个动作,动作完成后暂停,并把控制权交回主线程。你可以把一个动作理解为战术:运行一段命令序列、从文件 Y 中提取 X 等。不同于目的专用的子智能体,线程是通用的工人,服务于系统当前的意图。编排者决定接下来要做什么,线程去做它。普通子智能体是持久的,有时会在后台启动,并通过消息传递与主线程(或彼此)同步,因为它们的上下文隔离。相比之下,线程只用于在特定工作流中积累上下文,作为可复用的持久存储;它们并不把消息传递作为与编排器沟通的主要方式。取而代之的是,每个线程动作都会生成该动作序列历史的压缩表示。这个压缩表示称为 情节(episode),并直接与主线程共享。
Threads vs. Subagents: Context Isolation
用线程解决情节记忆
线程在完成一个动作时所经历的步骤构成一个 情节。这为 LLM 提供了一种可处理的、真正的情节记忆形式。
情节记忆是已完成情节的压缩表示:只保留重要结果,而不是保留到达结果所需的每一步战术痕迹。子线程不会与主线程进行来回消息传递,而是执行后返回情节。这个内建的完成边界使得在 Slate 架构中,compaction 变得自然。
情节也可以作为其他线程的直接输入,使线程可组合。一个线程可用此前线程的情节进行初始化,从而继承有用结论与工作历史,但不继承完整上下文。这种可组合性让线程式架构作为原语达到最大的可表达性,也正是它不同于只回传一条响应字符串的朴素子智能体设计之处。
线程编织
线程式执行的结果是:系统隐式且自适应地分解任务——无需静态计划。编排器不必提前承诺,但 必须 将工作外化为有界、可压缩的单元。这就是线程编织:编排器派发,线程执行,情节组合。
其机制是:编排器 通过引用 使用线程,从而具备复杂上下文路由的语义——类似 RLM 通过 REPL 达成的能力,但没有那种刚性,因为动作在一个线程内一步一步执行。由于线程范围有界,系统自然与当前计划同步。由于线程由 LLM 驱动而非静态脚本,它们能对意外的环境状态作出反应,而不是崩溃。
结果是一个隐式且自适应地分解任务的系统。编排器在推进中管理规划与分解;它无需提前承诺静态计划。但它 必须 把分解外化为有用的工作单元,这些单元可被压缩并在之后引用。频繁同步也意味着编排器能在任务过程中当新信息出现时更新策略。
Slate: Thread Weaving & Episode Architecture
线程即进程:LLM 系统的 OS 视角
线程与情节可以直接映射到操作系统式的框架。[26]
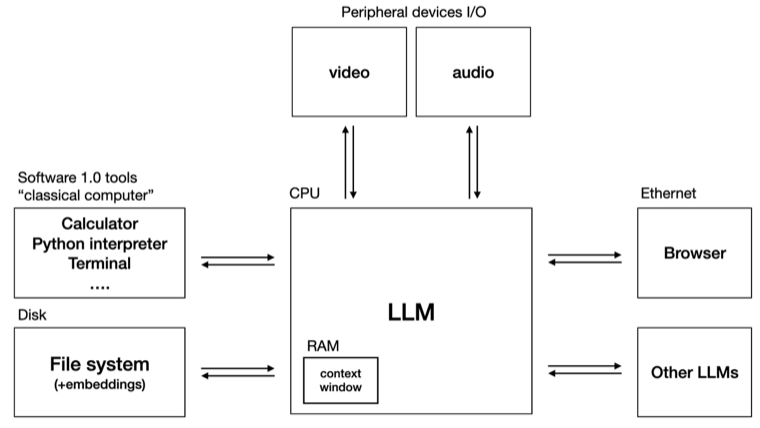
具体而言,Karpathy 的 LLM OS 观点把 LLM 视作操作系统内核:管理上下文(RAM)、生成进程(工具调用、子智能体)、读写存储(文件、记忆)、并协调外设(浏览器、终端、API)的 I/O。就像 OS 内核并不执行应用逻辑本身一样,主线程 LLM 负责调度任务、管理资源、维持进程状态,以把工作路由到系统之中。
Slate 的线程架构与此直接对应。编排层是内核。线程是隔离的进程。情节是进程的返回值:对进程所做工作的压缩总结,被提交回内核的工作记忆。文件系统、终端与网页是外设。模型的上下文窗口就是 RAM——稀缺、珍贵、并被积极管理。
在这个框架里,Slate 的情节架构给出了直接回应:不是让 RAM 填满直到进程崩溃,而是把每次线程返回视为一个自然的机会,去决定保留什么、压缩什么、丢弃什么。
长时程任务的瓶颈
长时程智能体任务的真正瓶颈是上下文管理,而不是模型智能。由于知识悬置,模型已经足够有能力解决比当前成功更多的任务。差距是系统问题,而非能力问题。
Slate 的路由之所以可用,本身就很惊人。模型似乎能理解如何在系统中以有用且恰当的方式路由上下文,而无需显式训练。我们把对这种路由行为的正式分析与基准测试留作未来工作。
而我们把 体验 它留给读者。
今天我们发布该智能体的开放 Beta。你可以访问我们的主页,或运行 npm i -g @randomlabs/slate 来使用它。
有趣的观察
在开发与测试中,有一些结果令我们意外:
- 在真实工作流中的大规模并行执行。 真实的软件任务会自然分解为并行的线程工作流。编排器可以同时派发多个线程,并在继续之前综合它们的情节。这在质量上区别于逐步执行的顺序型智能体,实践中也更快。
- 跨模型组合。 在同一任务中同时使用 Sonnet 与 Codex 的效果很好。情节边界提供了干净的模型切换交接点,不会损失上下文一致性。
参考文献
- RLM — 递归语言模型(论文)
- RLM — 博文概览
- Karpathy:LLM 作为计算机的框架
- TerminalBench 2.0:Simple Codex 基线
- Terminus 最小 harness
- Dex Horthy:“Dumb Zone”
- Altera:Project Sid / PIANO 架构
- Devin / Cognition:不要构建多智能体
- Manus:AI 智能体的上下文工程
- Manus:上下文工程笔记与幻灯
- Silver 等:AlphaZero(Science, 2018)
- AlphaZero 知识获取探针研究(PNAS)
- Stockfish vs LCZero:竞争范式
- Silver 等:AlphaGo(Nature, 2016)
- DeepMind:AlphaGo 的创新
- Stockfish 国际象棋引擎
- Geoffrey Huntley:Ralph 循环
- Amp:handoff 机制
- ADaPT:按需分解与规划
- TerminalBench 2.0:gpt2-codegolf 任务
- Yao 等:ReAct——推理与行动的协同
- Wei 等:链式思维提示
- Manus:架构幻灯
- Hong, Troynikov, Huber:Context Rot——输入 token 增加如何影响 LLM 性能(Chroma, 2025)
- 人类的工作记忆