去年在一次黑客松上,有人问我:“我能用你家 20 美元的 AI 订阅做出 Facebook 吗?”我尴尬地笑了。
现在你可以。信息流、个人主页、点赞、评论、认证,一整个周末,再加一个 20 美元的 Claude 订阅就行。可说实话?当我看到它跑起来时,并没有惊叹,反而有点失落。因为这个问题一开始就问错了。没人需要另一个 Facebook 克隆。代码从来都不是让 Facebook 值得万亿美元的原因。
代码现在可以批量生产了。可整个行业仍在倾尽全力把“生产代码”提升 10%。
这种努力有个名字:代理编排工程。我自己也花过真功夫:接过钩子、设计过多代理流程、调过子代理。可我反复得出的结论是:有用的部分并不新,新的部分又撑不久,经济账也从来算不通。老故事换了个新 buzzword。
把行话都剥掉,看看真正起作用的是什么。
“背压机制”“上下文防火墙”“渐进式披露”“黄金原则”——几个月的博客、会议演讲、arXiv 论文。
但你看看团队几个月迭代后真正留下来的,总是同一套东西:测试、linter、CI、清晰的文档、git 纪律、架构契约。让代理能验证自己的输出。
这些书我们三十年前就有了。把“写好测试”称作 AI 革命,就像把“洗手”叫做医学突破。对,重要,但不新。
真正新颖的部分:子代理编排、推理三明治、基于 trace 的优化——肮脏的秘密是,多数复杂东西都可以拿掉,结果几乎不变。
Pi 这个自称“极简终端编码编排”的编码代理,啥都没有:没有子代理、没有计划模式、没有 MCP。只有模型、文件工具和 shell。人们每天都用它交付真实的软件。有时候,少反而更多。
价值曲线是阶跃函数。我们早就跨过去了。
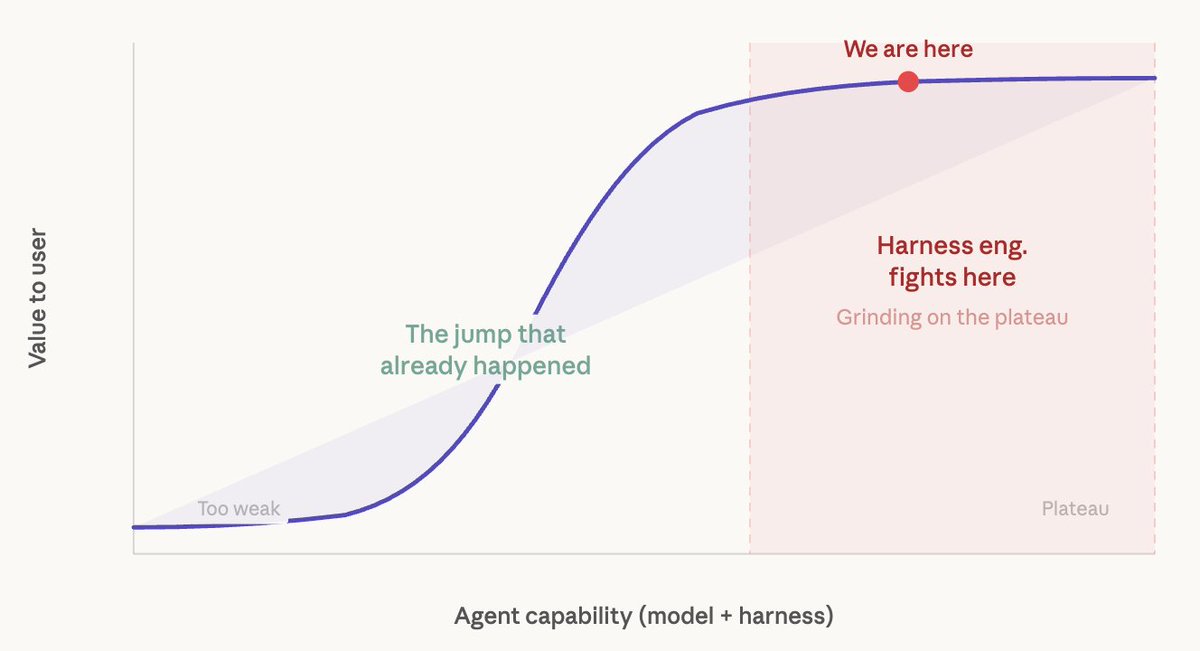
任务要么完成,要么没完成。没有什么“完成了 73%”。模型在过去一年越过了这个阈值。这才是重要的跃迁。代理编排工程活在它之后的平台期——在一个微不足道的基线和 Terminal Bench 上最好的编排之间打磨,而一次模型升级就能免费给你 5–10 分。
下一个巨大跃迁来自下一个模型,而不是更多中间件。
没有乘数效应。
Google 把 85 亿次日搜索的 CTR 提升 1% = 每年约 15 亿美元。相同优化,数十亿次同质交易。这就是乘数效应。
编码没有。每个任务都是离散的。可靠性提高 15% = 普通开发者每隔几天多完成一个任务。而且不像广告,人还在回路里,他们会看输出、评判它,需要时会重跑。
AI 把代码供给大幅扩张了,边际成本趋近于零。可需求没变:值得解决的问题数量、愿意付费的用户、分发难度,全都没变。
一万个人这个周末都能做出 Facebook,但仍然只有一个值得用——那个有你朋友的。约束从来不是“我们能不能写出代码”。
还有一点我觉得这场编排讨论一直忽略:几乎零成本、每秒 1000 tokens 的 Opus 4.6,可能比今天价格下的 Opus 5 更重要。当推理几乎免费时,你不需要聪明的编排来让第一次就成功。并行跑 20 次,让 CI 选赢家。重试成本趋近于零时,蛮力胜过优雅。
我觉得这之所以流行,是因为这几乎是我们唯一能做的事。
我不是在否定。我也包括自己。
你训练不了模型,那是 Anthropic 和 OpenAI 的工作。你控制不了定价或推理速度。你改不了公司的产品市场契合。你也“变不出”用户。
但你可以改 AGENTS.md,可以加一个 hook,可以接一条子代理。于是你就做了,而且感觉像在工程,因为确实是:你写代码、测量、迭代。它有真实、有效工作的形状。
但我觉得我们应该诚实地问自己:这真是我们该把时间花在的地方吗?还是我们只是在优化手能摸到的东西,因为真正重要的东西——产品、分发、单元经济——更难也更吓人?
我没有一个干净的答案,但我觉得这个问题值得坐下来好好想。
如果只有一件事值得做:
让你的代码可被代理自证。类型系统。能快速失败的测试。代理能触发并读懂的 CI。模块之间清晰的契约。
这才是杠杆。每个花哨的编排组件都在试图复刻一个简单想法:给代理一个明确无歧义的信号,告诉它输出是否正确,然后让它迭代。如果你的代码库能做到这一点,代理会用任何编排把剩下的事情做完,不管多简单。
agent = model + harness
harness 这一项每个季度都在缩小。
agent ≈ model
现在的游戏是成本和速度。这两者都不是编排能解决的。
我知道有人会不同意,这没关系。如果你在做编排、它确实让你更快交付,那就继续。但如果你一直隐隐觉得自己花在“配置代理”上的时间比真正“用它去做事”还多,也许该退一步,问问真正的瓶颈是什么。
代码从来都不是难点。老故事。