亲爱的朋友们:
在美国以及许多其他国家,求职者正面对一个艰难的环境。与此同时,关于“AI 会导致大规模失业”的担忧——至少到目前为止——被夸大了。不过,对 AI 技能的需求正在开始推动就业市场发生变化。我想分享一下我在一线看到的情况。
首先,过去一年里,许多科技公司裁掉了员工。有些 CEO 把原因归结为 AI——认为 AI 在做这些工作,所以不再需要人——但现实是,AI 现在还没那么好用。很多裁员其实是在纠正疫情期间的过度招聘,或是一般性的成本削减与组织重组;这些事情在现代 AI 出现之前也偶尔会发生。除了少数岗位之外,几乎没有裁员是因为工作被 AI 自动化所导致。
当然,这种情况未来可能会扩大。目前一些高度暴露在 AI 自动化风险下的职业,比如呼叫中心坐席、译者和配音演员,可能会更难找到工作并/或看到薪资下降。但“广泛失业”的说法被炒得太过头了。
相反,一句常见的论断更贴近现实:AI 不会取代工人,但会用 AI 的工人会取代不会用 AI 的工人。举例来说,由于 AI 编程工具能让开发者效率大幅提升,懂得如何使用它们的开发者正变得越来越抢手。(如果你也想成为其中一员,欢迎学习我们的短课:Claude Code、Gemini CLI 和 Agentic Skills!)
因此,AI 的确正在导致失业,但方式更微妙。一些企业正在淘汰那些不适应 AI 的员工,并用能够适应的人来替换。这一趋势在软件开发领域已经非常明显。此外,从许多初创公司的招聘模式中,我也看到了这种人员替换在传统上被认为“非技术”的岗位上出现的早期迹象。懂得用 AI 来写代码的市场人员、招聘人员、分析师,比不懂的人更高产,因此一些公司正逐步与无法适应的员工分道扬镳。我预计这种情况会加速。

与此同时,当公司组建“AI 原生”的新团队时,新团队有时会比被替换掉的团队更小。AI 让个体更有效率,从而让缩减团队规模成为可能。比如,随着 AI 让软件构建更容易,瓶颈正在转向“决定做什么”——这就是所谓的 产品管理(PM)瓶颈。过去可能需要 8 名工程师和 1 名 PM 的项目,现在也许只需要 2 名工程师和 1 名 PM,甚至可能只需要一个同时具备工程与产品能力的人。
对员工来说,好消息是:大多数企业要做的事很多,但人手不够。具备合适 AI 技能的人常常会获得更多机会,承担更多职责,甚至去处理那长长的、过去因为效率不足而无法执行的想法清单。如今我看到许多企业里的员工正在挺身而出,去打造能帮助业务的新东西。机会很多!
我知道这些变化令人压力山大。我对每一个被裁员影响的家庭、每一个找不到理想岗位的求职者、以及更多担心未来职业前景的人,感同身受。幸运的是,我们仍有时间去学习,并为就业市场的走向做好定位。就 AI 而言,绝大多数人——无论技术或非技术——都还站在起跑线附近,或者不久前还在起跑线上。因此,现在依然是持续学习、持续构建的绝佳时机;而这样做的人,将拥有大量机会。
Andrew
来自 DEEPLEARNING.AI 的信息

“Document AI: From OCR to Agentic Doc Extraction” 探索文档系统如何超越纯文本提取。学习视觉优先、具备代理能力(agentic)的流水线如何在保留版式、表格与图表的同时,将 PDF 解析为结构化的 Markdown 与 JSON。与 LandingAI 合作打造。立即报名
新闻
Agents Unleashed
开源 AI Agent —— OpenClaw 突然走红,引发了人们对“代理式未来”的兴奋、担忧与炒作。
发生了什么: 11 月,开发者 Peter Steinberger 发布了 OpenClaw —— 这款产品此前曾名为 WhatsApp Relay、Clawdbot 和 Moltbot —— 作为个人 AI 助手,用于管理日历、总结邮件、发送提醒等任务。1 月下旬,众包科技新闻网站 HackerNews 上的一篇帖子 提到 了该项目,随后迅速爆发,获得了 GitHub stars 增长最快的纪录,并带来了比 Claude Code 更多的 Google 搜索。
- 在短短几天内,这个最初设计为在 MacOS 或 Linux 上本地运行的项目就吸引了 200 万访客,并累积了数百万次安装。为了让代理 24/7 运行,爱好者们纷纷去买专用(且隔离)的机器,导致 Mac Mini 一度断货。
- 用户 指挥 OpenClaw 代理整理日程、监控 vibe-coding 会话,并发布到个人网站与通讯。一位用户让它 构建子代理;一周之内,他声称自己被代理的 电话 吵醒:代理“自主地”注册了电话号码、接入了语音 API,并一直等到早上才问“什么事?”
- 科技创业者 Matt Schlicht 推出了 Moltbook——一个类似 Reddit 的社交讨论网络,设计目标是由 OpenClaw 代理来撰写、阅读与整理。到那周末,OpenClaw 用户已指挥超过一百万个代理去注册账号。在提示语或仅凭其创建者写在默认记忆文件中的描述推动下,Moltbook 的代理成员把网站塞满了宣言、生活故事与垃圾信息。
- 与此同时,用户竞相堵漏洞,代理活动却造成了成本超支、私密凭据暴露与安全事件。
它是怎么工作的: OpenClaw 是一个可配置的代理式框架,可运行在本地电脑或云端虚拟机中。用户可以构建能够浏览和写入本地文件系统的代理,或让其在预定义的沙箱中活动。他们也可以授权代理使用云服务,例如邮件、日历、效率工具、语音转文字与文字转语音应用,以及几乎任何能通过 API 响应的服务。代理还可以使用编程工具(例如 Claude Code)、在社交网络上互动、抓取网站,并代用户花钱。
- 架构: OpenClaw 由一个中央网关服务器与多种客户端应用组成(例如聊天、浏览器会话、云服务等)。它会在启动时生成动态系统提示词,并通过 Markdown 文件在会话之间维护持久记忆。
- 记忆: 默认记忆文件包括 USER.md(用户信息)、IDENTITY.md(代理信息)、SOUL.md(约束代理行为的规则)、TOOLS.md(工具信息)以及 HEARTBEAT.md(指示代理何时以及如何连接不同应用)。代理和用户都可以编辑这些文件。
- 模型: 系统通过用户所选的 AI API 对用户进行认证。默认是 Anthropic Claude Opus 或 Meta Llama 3.3 70B,但 OpenClaw 也支持来自 Google、OpenAI、Moonshot、Z.ai、MiniMax 等开发者的模型,可在本地或云端托管。OpenClaw 本身免费,但模型托管方可能会按输入/输出 token 收费。
- 用户界面: 用户可通过聊天机器人或消息服务与代理沟通并下达指令,包括 Telegram、WhatsApp、Slack、iMessage、Google Chat 等。
- 技能: 安装包包含数十种技能,从读取与发送邮件、创建日历邀请,到控制家中音箱或灯光。其他技能可通过命令行或 ClawHub(一个包含数百个用户贡献扩展的公共目录)安装。大多数技能基于开源命令行应用,通过公共 API 交互。
是的,但是: OpenClaw 与 Moltbook 最初上线时存在大量 安全漏洞 与其他问题,其中一些在撰写本文时已被修复。一个开放式系统、不安全的设计与缺乏经验的用户组合在一起,带来了各种漏洞:配置不当的 OpenClaw 部署 暴露 了 API 密钥,Moltbook 暴露 了更多达数百万的数据。为窃取数据等恶意任务设计的技能也已 泛滥。许多用户把系统安装在专用机器上,以免把私密数据暴露给攻击者,或是给那些“出于好意但容易闯祸”的代理。
为什么重要: OpenClaw 引发了巨大关注,让 AI 社区中的知名人士开始争论其新颖性与重要性。对开发者而言,OpenClaw 提供了一个高度可定制、功能强大的 AI 助手,但需要非常谨慎的安全措施。它也让我们瞥见一个未来:自主代理在几乎不需要人类输入的情况下,忙着自己的业务。
我们的看法: 作为一个富于想象力与进取心的开源项目,OpenClaw 引发的炒作可能远超其实际。媒体 报道 把 Moltbook——其内容与自 GPT-3 以来让世人惊叹与发笑的 LLM 输出并无本质区别——比作 AGI 或奇点的到来。我们想强调:代理还远没到那一步,甚至差得很远。相反,OpenClaw 展示的是:代理可以非常有用,我们仍在寻找好的用例,而我们必须密切关注安全问题。以及,你永远不知道你的某个开源项目什么时候会突然起飞!
Kimi K2.5 组建了自己的“劳动力”
一个开源视觉-语言模型释放出“打工小弟”代理,让它能更快、更有效地完成任务。
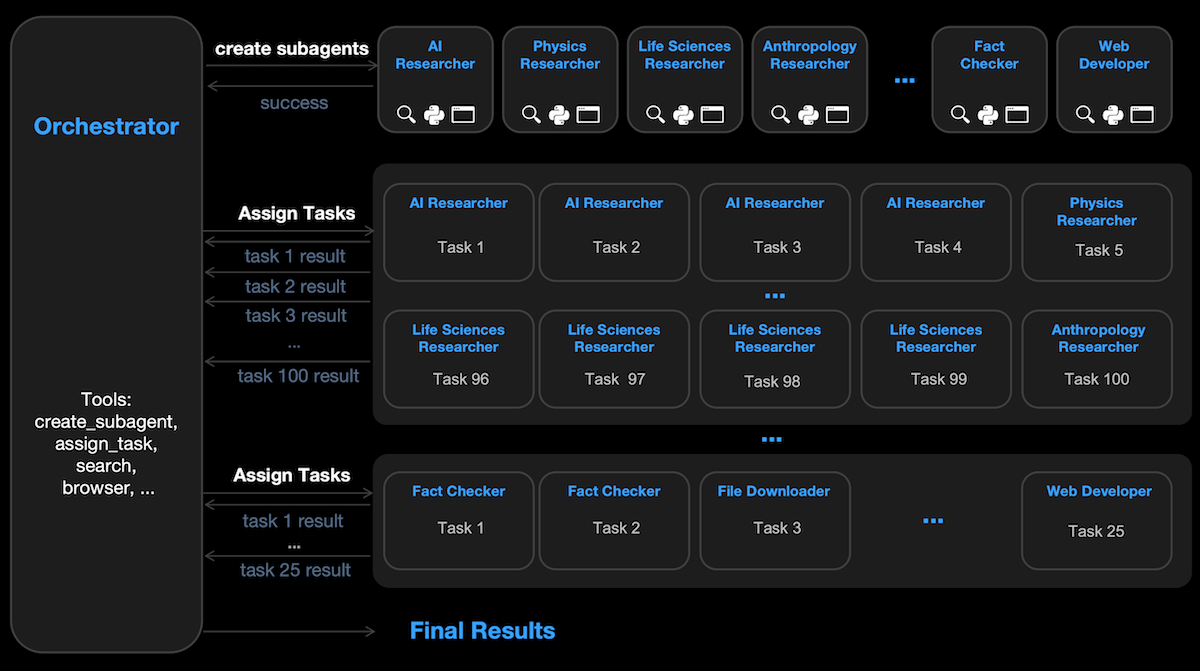
最新进展: Moonshot AI 发布了 Kimi K2.5——其 Kimi K2 大语言模型的更新版本,新增了视觉能力,并支持生成作者所谓的子代理(subagents):并行工作流,可控制独立模型来执行 AI 研究、事实核查与 Web 开发等任务,并将任务分派给它们。
- 输入/输出: 文字、图像、视频输入(最多 256,000 tokens);文字输出(每秒 109.5 tokens)
- 架构: MoonViT 视觉编码器(4 亿参数),混合专家(MoE)Transformer(总计 1 万亿参数,每 token 激活 320 亿)
- 性能: 在 Artificial Analysis Intelligence Index 上领先所有其他开源权重模型
- 可用性: 免费的 Web 界面,权重可免费 下载(可用于非商业与商业用途,但需署名,许可为修改版 MIT license),API 价格:每百万输入/缓存/输出 tokens 分别为 $0.60/$0.10/$3.00,coding assistant 每月 $15 到 $200
- 特性: 工具调用、Web 搜索、可选推理模式、子代理
- 未披露: 训练数据、训练方法
它是怎么做到的: Moonshot 很少披露 Kimi K2.5 的构建细节;它公开的信息包括:
- Kimi K2.5 基于 Kimi K2-Base(7 月发布的纯文本模型)。团队加入了视觉编码器,并在 15 万亿图像与文本 tokens 上对基础模型做了进一步预训练。
- 通过强化学习,团队训练 Kimi K2.5 在给定提示词时,能够生成并行运行的子代理、向它们分配任务,并把它们的输出整合进最终回答。Kimi K2.5 会因为“实例化子代理并正确解决问题”而获得奖励。例如,当提示它找出 100 个领域中排名前三的 YouTube 频道时,Kimi K2.5 学会了为每个领域收集信息,生成 100 个领域专属子代理去搜索 YouTube,然后把发现汇总进电子表格。
结果: 在 Artificial Analysis Intelligence Index(10 个基准的加权平均)中,开启思考模式的 Kimi K2.5 超过 了所有其他开源权重模型。在 Moonshot 的测试中:
- 思考模式下的 Kimi K2.5 在推理、视觉、编码与代理式行为等多项指标上超过所有开源权重模型。在部分视觉与代理式基准上,它也超过了闭源模型,包括将 GPT 5.2 设为 xhigh、Claude 4.5 Opus 设为 extended thinking、以及 Gemini 3 Pro 设为 high thinking。
- 在 17 个图像与视频相关基准中,Kimi K2.5 在 9 个上取得最高分,超过 GPT 5.2(xhigh)、Claude 4.5 Opus(extended thinking)与 Gemini 3 Pro(high thinking)。
- 子代理让 Kimi K2.5 的速度提升到“不用子代理”时的 3 到 4.5 倍。在代理式基准 BrowseComp 与 WideSearch 上,子代理分别带来 18.4 和 6.3 个百分点的提升。
是的,但是: Moonshot 没有披露 Kimi K2.5 使用子代理所带来的算力与内存成本,因此速度/性能与资源需求之间的权衡并不明确。
新闻背景: Kimi K2.5 在 Moonshot 初代视觉-语言模型(规模小得多、160 亿参数的 Kimi-VL)发布 7 个月后到来;Kimi-VL 同样使用了 MoonViT 视觉编码器。
为什么重要: 构建一个代理式工作流可以提升模型在特定任务上的表现。与预先定义的代理式工作流不同,Kimi K2.5 会自行决定何时需要新的子代理、子代理应该做什么、以及何时把工作委派出去。这种自动化的代理编排提升了并行任务的表现。
我们的看法: Kimi K2.5 把任务执行从“链式推理”转向“代理式团队协作”。它不再按顺序逐步响应提示词,而是像一个管理者一样,调度多个独立工作流/模型并行完成不同部分。

在 25 周年之际,Wikipedia 以高调的合作协议庆祝:通过让 AI 公司更容易使用其数据来训练模型,换取对方的资金支持。
最新进展: Wikimedia 基金会 宣布 与包括 Amazon、Meta、Microsoft、Mistral AI 和 Perplexity 在内的 AI 公司建立合作。该合作项目名为 Wikimedia Enterprise,使合作方能以更高速度、更大吞吐量访问 Wikipedia 数据,而不必像过去那样抓取网页。财务条款未披露。
它是怎么运作的: 除了用户捐赠之外,企业合作是 Wikimedia Foundation 的主要收入来源。 Wikimedia Enterprise 提供 API,使开发者能够直接访问百科条目与其他 Wikimedia 数据,包括 Wikimedia Commons 图片、Wiktionary 在线词典,以及 Wikidata 机器可读知识库。免费计划提供有限的数据更新与支持门户访问。付费计划(条款不公开)可能包含每日快照、潜在的无限数据请求(限制取决于订阅价格)、实时修订的流式访问,以及人工技术支持。
- Wikipedia 数据遵循知识共享许可,允许商业与非商业用途的免费使用。其免费可用性与高质量,使其成为训练 AI 模型的重要数据源。基金会也提供一个用于非商业 AI 训练的开源 Kaggle 数据集。
- Wikipedia 收到来自自动化 Web 爬虫的请求数量远超人类用户。网站创始人 Jimmy Wales 表示,爬虫抓取数据以训练 AI 系统,使基金会的托管、内存与服务器成本飙升。基金会 呼吁 AI 开发者提供资金支持,使用 API 而不是抓取网页,并为从 Wikipedia 条目衍生的信息进行署名。
- Microsoft、Mistral AI 与 Perplexity 都在过去一年内成为企业合作伙伴。Wikimedia 与 Amazon、Meta 的既有合作此前并未公布。Google 于 2022 年成为 Wikimedia Enterprise 合作伙伴。
- Wikimedia 也宣布与一些规模较小的公司合作;这些公司都强调其环保取向:Ecosia(搜索引擎公司)、Pleias(LLM 构建者)与 ProRata(AI 搜索、广告与署名引擎)。
新闻背景: 其他内容广泛被用于训练 AI 的出版方也在尝试向 AI 公司收费,成功程度不一。2023 年,Reddit 与 Stack Overflow 宣布 计划在寻求许可协议的同时保护其数据不被 AI 爬虫抓取。Reddit 与 Google、OpenAI 等达成了许可协议,让对方使用其内容训练模型。Stack Overflow 的流量与提问量则 暴跌:从 2014 年每月 20 万个问题,降至 2025 年末每月 5 万个问题。随着用户从在网站上讨论技术问题转向向 AI 模型提问,公司从“以广告为主要收入”转向“把数据打包出售用于 AI 训练”。
为什么重要: AI 公司希望在 Wikipedia 上训练模型,而用 API 调用收集数据比抓取网页要快得多——更不用说为了跟上百科不断更新的节奏,爬虫必须以极高频率抓取。与此同时,Wikipedia 需要收入才能生存。出售 API 访问既能为开发者提供有价值的服务,也能为这一关键数据源建立更稳固的财务基础。
我们的看法: 这些交易是双赢。喜欢用传统方式阅读在线百科的人照旧可以继续读;构建 AI 模型的人也能更安心,因为他们不会“误杀”这一重要训练数据来源。
更小但更强的模型配方
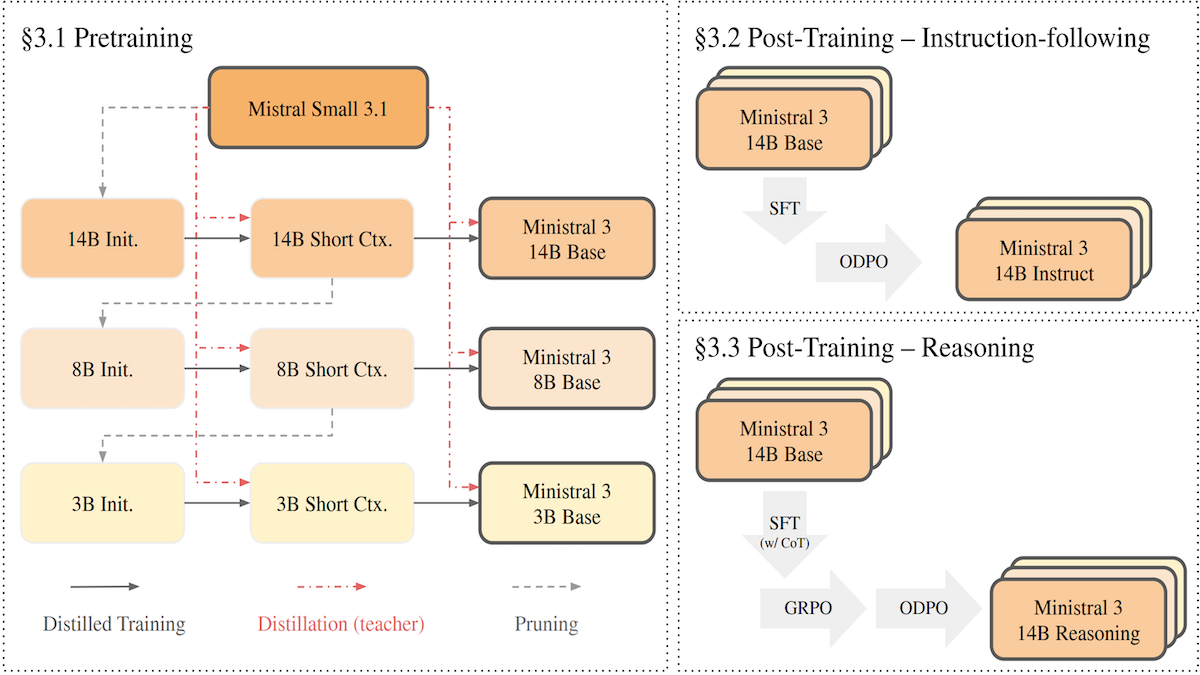
Mistral 把 Mistral Small 3.1 压缩到更小的版本,得到一个相对小规模、开源权重、视觉-语言模型家族;在一些指标上,它们比同等规模的竞争对手更强。该方法结合了剪枝与蒸馏。
最新进展: Mistral AI 发布 了 Ministral 3 系列的权重,参数规模分别为 140 亿、80 亿与 30 亿。每个规模都提供 base、instruction-tuned 和 reasoning 变体。团队在一篇 论文 中详细说明了其蒸馏配方。
- 输入/输出: 文本与图像输入(最多 256,000 tokens;推理变体最多 128,000 tokens),文本输出
- 架构: 仅解码器(decoder-only)Transformer
- 性能: Ministral 3 14B Base(140 亿参数)与 Mistral Small 3.1 Base(240 亿参数)非常接近,其他更小模型紧随其后
- 特性: 工具使用、多语言(英语、法语、西班牙语、德语、意大利语、葡萄牙语、荷兰语、中文、日文、韩文、阿拉伯语)
- 可用性: 权重可在 Apache 2.0 license 下免费 下载,API 价格:每百万输入/输出 tokens 为 $0.20/$0.20(Ministral 3 14B)、$0.15/$0.15(Ministral 3 8B)、$0.10/$0.10(Ministral 3 3B)
- 未披露: 训练数据
它是怎么做到的: 团队采用一种他们称为“级联蒸馏”(cascade distillation)的方法来构建模型。从更大的父模型开始,他们交替进行剪枝(移除不重要的参数)与蒸馏(训练更小模型去模仿大模型输出),逐步得到更小的子模型。
- 团队先将 Mistral Small 3.1(240 亿参数)剪枝得到 Ministral 3 14B,并以此作为 Ministral 3 8B 等后续模型的起点。
- 他们通过移除那些对输入改变最小的层来剪枝,然后缩小内部表征以及全连接层的宽度。
- 随后训练剪枝后的模型去模仿 Mistral Small 3.1。与直接模仿更大、更强的 Mistral Medium 3(参数规模未披露)相比,让剪枝模型在预训练阶段模仿 Mistral Small 3.1 产生了更好的结果。不过,在后续的微调阶段,剪枝模型也受益于学习模仿 Mistral Medium 3。
- 为了让模型更好地遵循指令,团队先用“期望行为”的示例进行训练,然后使用 ODPO 进一步精炼;该技术利用 LLM 比较更好与更差的回答,从而把模型引导到更偏好的输出。
- 为了产生推理变体,团队在数学、编程、多语言任务、工具使用与视觉推理等“分步推理示例”上训练模型,然后用 GRPO 进一步提升表现。
性能: Ministral 3 14B(版本未说明)在 Artificial Analysis Intelligence Index 上排在 Mistral Small 3.1 与 Mistral Small 3.2 之前;该指数是 10 个基准的加权平均。Mistral 将 Ministral 3 与 Mistral Small 3.1 以及同等规模的开源权重竞争对手进行比较。Ministral 3 14B base 在数学与多模态理解测试上比 Mistral Small 3.1 高 1 到 12 个百分点,在 Python 编码上打平;它也在 GPQA Diamond 上超过了父模型。与同规模竞争对手相比:
- Ministral 3 14B:在 TriviaQA 上,Ministral 3 14B base(74.9% 准确率)超过 Qwen 3 14B(70.3%),但落后于 Gemma 3 12B(78.8%)。在 MATH 上,Ministral 3 14B base(67.6%)超过 Qwen 3 14B(62%)。其他方面二者相近。在 AIME 2025(高中竞赛数学题)上,Ministral 3 14B reasoning 达到 85% 准确率,而 Qwen 3 14B Thinking 为 73.7%。
- Ministral 3 8B base 在除 TriviaQA 之外的大多数基准上超过更大的 Gemma 3 12B。
- Ministral 3 3B base 与 Gemma 3 4B、Qwen 3 4B 竞争力相当,但在 MATH 上强很多。
为什么重要: 级联蒸馏为“从单一父模型以远低于常规的成本产出一个高性能模型家族”提供了一条路径。训练 Ministral 3 所需的训练 tokens 约为 1 万亿到 3 万亿;而同规模的 Qwen 3 与 Llama 3 模型则需要 15 万亿到 36 万亿 tokens。训练时间也更短,训练算法相对简单。这类方法可以帮助开发者在不成比例增加成本的情况下,构建多个不同规模的模型。
我们的看法: Ministral 3 模型可以在普通笔记本与智能手机上运行。边缘端的本地 AI 正变得越来越强、竞争力越来越高。